
Every data engineer knows the pain of managing chaotic pipelines, brittle scripts, and never-ending integration issues. The best data engineering tools offer a way out—turning fragile setups into scalable, reliable systems that can handle everything from ELT to orchestration, streaming, and analytics.
Modern data stacks are no longer about monoliths but about assembling the right tools for each job, often combining open-source flexibility with cloud convenience.
Data storage: structured, unstructured, and everything in between
For companies with primarily structured data, relational databases remain the go-to choice. Enterprise players often lean on stalwarts like Oracle or SQL Server, typically deployed in hybrid environments blending on-premise infrastructure with the cloud. However, the pragmatic choice for many modern organizations is PostgreSQL: a robust, open-source relational database that’s evolved into a highly capable, production-grade system over the last decade.
When data becomes less structured—media files, logs, or semi-structured formats like JSON—cloud storage solutions take over. AWS S3, Azure Blob Storage, and Google Cloud Storage dominate this space, offering scalable and cost-effective blob storage. These platforms pair well with serverless query engines such as AWS Athena, Google BigQuery, or Azure Synapse—though Synapse is rumored to be heading toward retirement, with Microsoft Fabric taking its place as the all-in-one analytics solution.
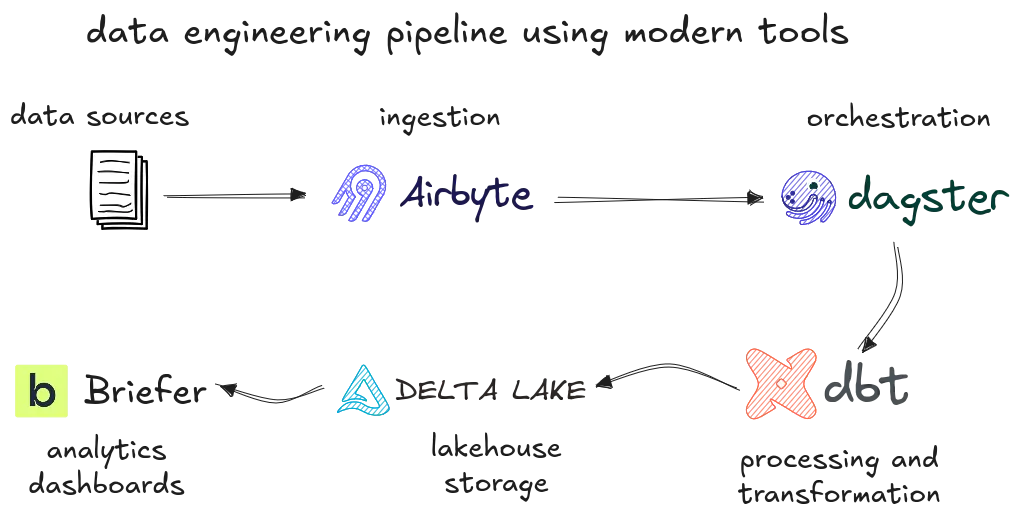
Data ingestion: getting data where it needs to be
Extracting and loading data has come a long way from bespoke Python scripts cobbled together at midnight. Open-source tools like Airbyte have made a splash by offering a modular, connector-based approach to ELT, letting engineers quickly integrate APIs, databases, and SaaS platforms without reinventing the wheel. Airbyte's community-driven connector model means it's constantly expanding, catering to niche and mainstream needs alike.
For organizations willing to trade control for convenience, Fivetran offers a managed ELT platform that shines in reliability and breadth of pre-built connectors. It’s often the preferred choice for companies with sufficient budget and a desire to minimize maintenance overhead.
Meanwhile, Meltano continues to champion the open-source ethos, giving data teams more flexibility and control over their pipelines, particularly in development-centric environments. Cloud-native tools like AWS Glue and Azure Data Factory also provide serverless ingestion pipelines, though they often lag behind in API connector diversity.
Orchestration: keeping pipelines under control
Once the data starts flowing, orchestration becomes paramount. Apache Airflow has cemented itself as the industry standard for managing complex workflows, offering fine-grained control, extensibility, and a thriving ecosystem of plugins and integrations. Its directed acyclic graph (DAG) paradigm lets teams model dependencies clearly, although it can introduce operational overhead.
from airflow import DAG from airflow.operators.bash import BashOperator from datetime import datetime with DAG('etl_pipeline', start_date=datetime(2025, 1, 1), schedule_interval='@daily') as dag: extract = BashOperator(task_id='extract', bash_command='python extract.py') transform = BashOperator(task_id='transform', bash_command='python transform.py') load = BashOperator(task_id='load', bash_command='python load.py') extract >> transform >> load
For teams prioritizing developer experience and type safety, Dagster has emerged as a compelling alternative. Built with modern software engineering practices in mind, Dagster encourages testability and structured config management, making it particularly appealing for teams that treat data pipelines as production-grade software.
In some cases, managed services like AWS Glue Workflows or Azure Data Factory may be sufficient, especially when sticking within a single cloud ecosystem, but they often lack the flexibility and ecosystem breadth of open-source tools.
Processing and transformation: making data usable
Batch and stream processing used to be synonymous with Hadoop, but that era has largely passed. Today, Apache Spark reigns supreme, capable of handling both batch jobs and real-time streams with its powerful distributed computation engine. Spark is often deployed on managed platforms like Databricks, which has led the evolution of the lakehouse architecture, blending low-cost object storage with structured, scalable query layers via Delta Lake.
Databricks' lakehouse model offers teams the ability to process massive datasets efficiently while enforcing data reliability through ACID transactions. Originally tied to Azure Databricks, the platform has since expanded to AWS, making it more cloud-agnostic and appealing to a broader user base.
Challenging Databricks in the lakehouse space is Dremio, an open-source SQL query engine that uses Apache Iceberg or Delta Lake as table formats. Dremio offers the ability to store data in S3 or other cloud storage solutions while providing performant, ANSI SQL-compliant queries without the need to load data into a traditional warehouse. Its focus on open formats and cost-effective compute makes it attractive to organizations wary of vendor lock-in.
When it comes to transformation, dbt (data build tool) has become indispensable. By popularizing SQL-based, version-controlled transformations, dbt bridges the gap between data engineers and analysts, promoting maintainability and transparency in transformation logic. Its support for testing, documentation, and modular development patterns has redefined how modern teams approach data modeling.
-- models/orders_transformed.sql with raw_orders as ( select * from {{ ref('raw_orders') }} ) select order_id, customer_id, total_amount, order_date::date from raw_orders where status = 'completed'
Analytics and dashboards
All these engineering feats ultimately support one goal: turning raw data into insights. This is where analytics platforms and dashboards step in. Traditional business intelligence tools offer robust reporting capabilities, but teams seeking to simplify the analytics process, especially when working with Python and AI, turn to Briefer.
Briefer enables data teams to rapidly transform datasets into clean, shareable dashboards and analysis—bridging the gap between data engineering and business outcomes. Its Python-native design makes it particularly well-suited for data scientists and engineers who prefer working in code-first environments but need to deliver polished outputs.
Conclusion
The modern data engineering toolkit is a far cry from its humble beginnings, now consisting of specialized tools optimized for distinct layers of the data stack. Whether it’s orchestrating complex workflows with Airflow, transforming datasets with dbt, or building scalable lakehouses with Databricks or Dremio, the best data engineering tools empower teams to build reliable, scalable, and maintainable systems.
Turn complex data pipelines into clean, actionable insights. Try Briefer today and simplify your analytics, accelerate your impact. Get started for free!