
It's not easy to find equilibrium between complex and simple when training a Machine Learning model. Darts-based explanations about Bias-Variance tradeoff never convinced me, so I decided to break it down: what’s really behind this dilemma?
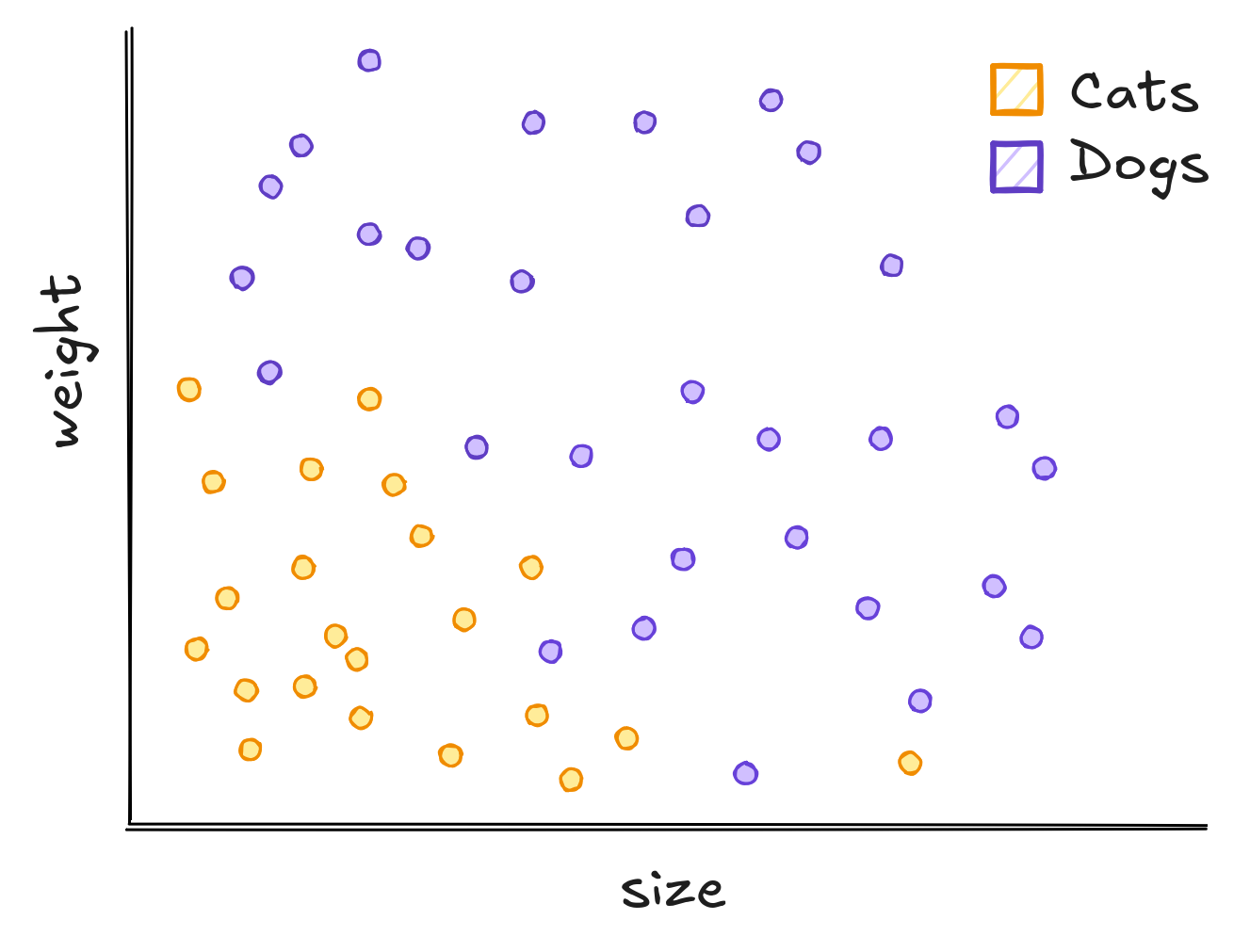
Imagine everyday lots of dogs and cats pass through your window. Some of them are big, some are small ones. You decide to classify them by height and weight, so you take measures for a bunch of animals. Cats are usually smaller and lighter. Dogs are generally bigger or heavier.
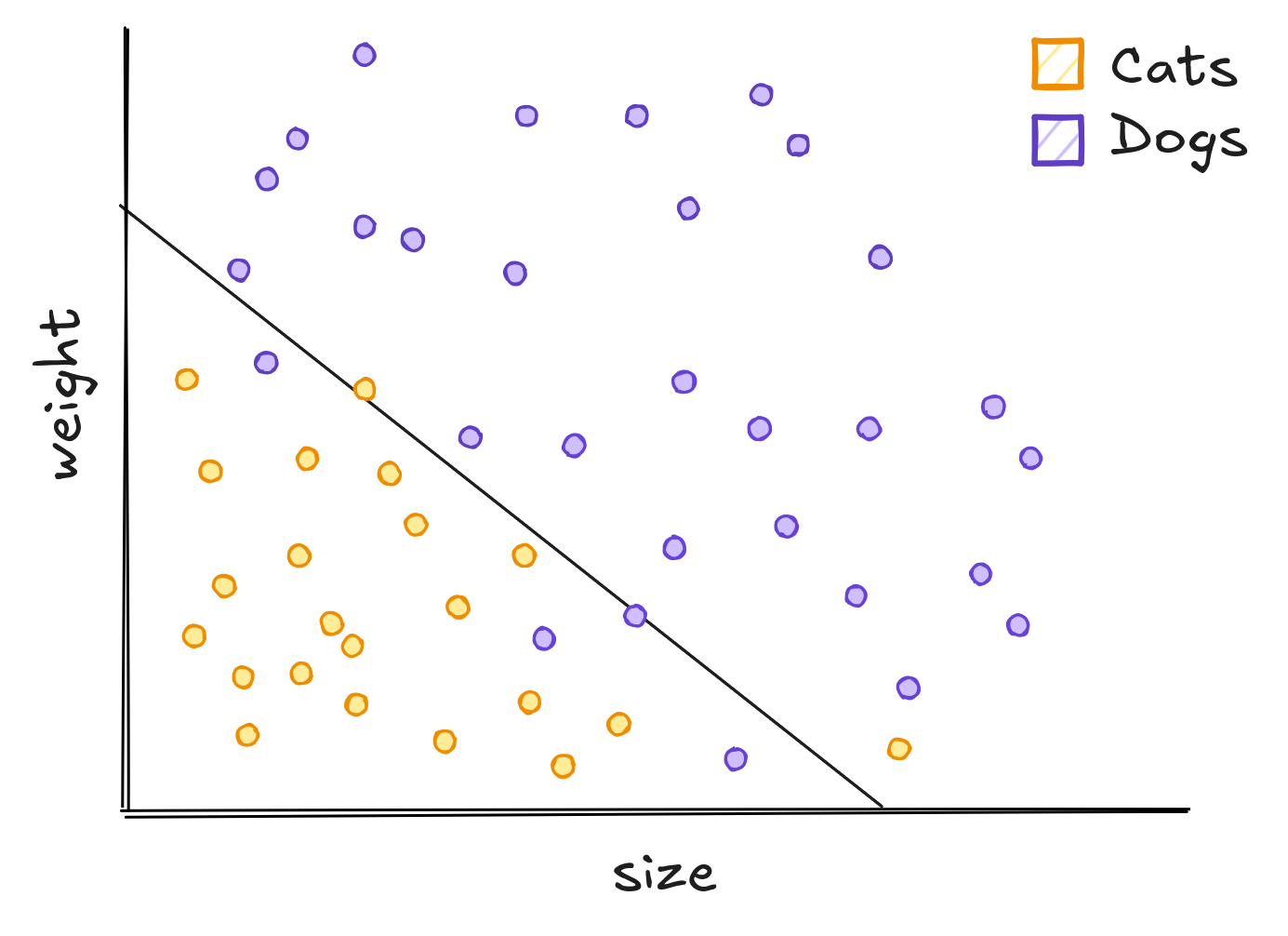
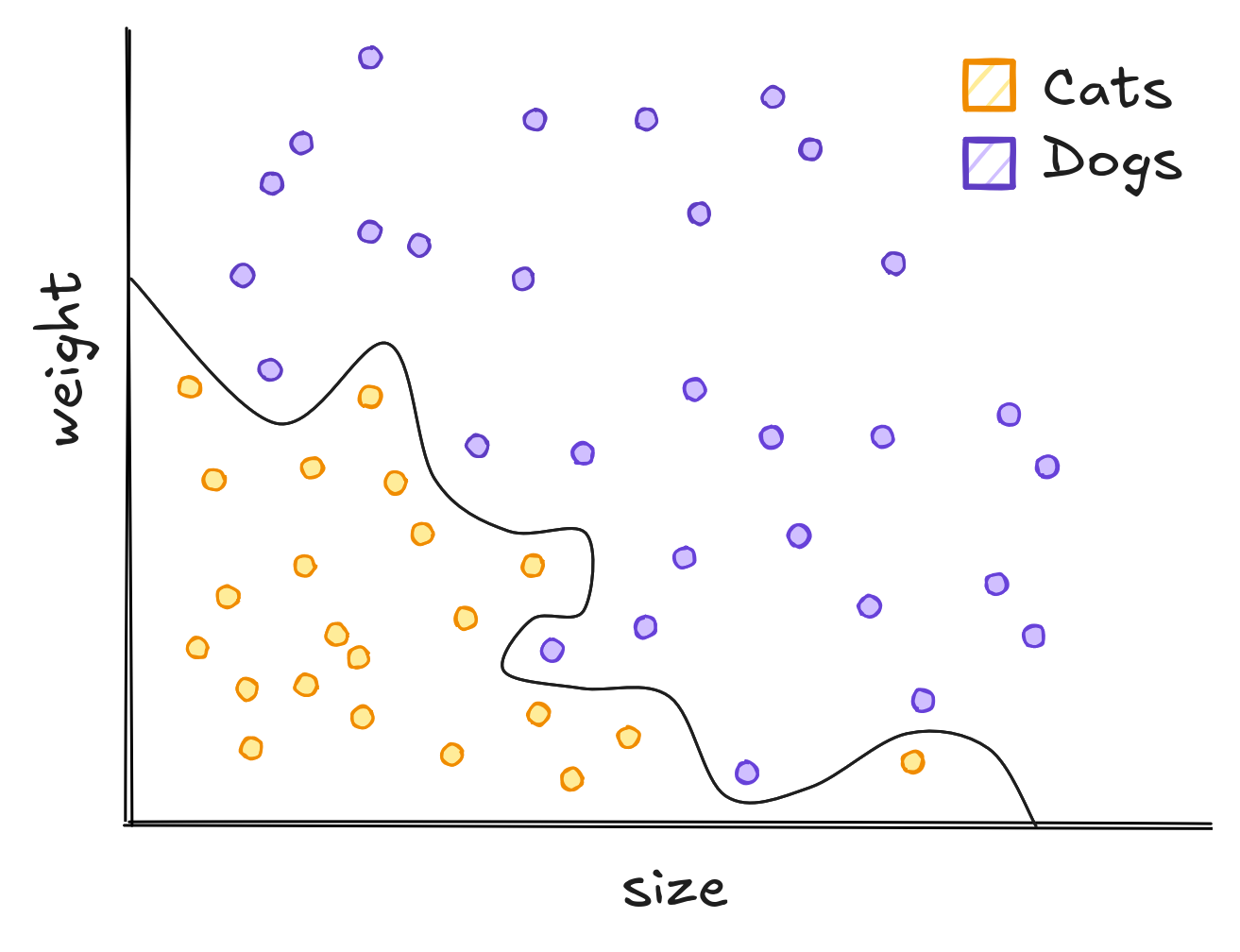
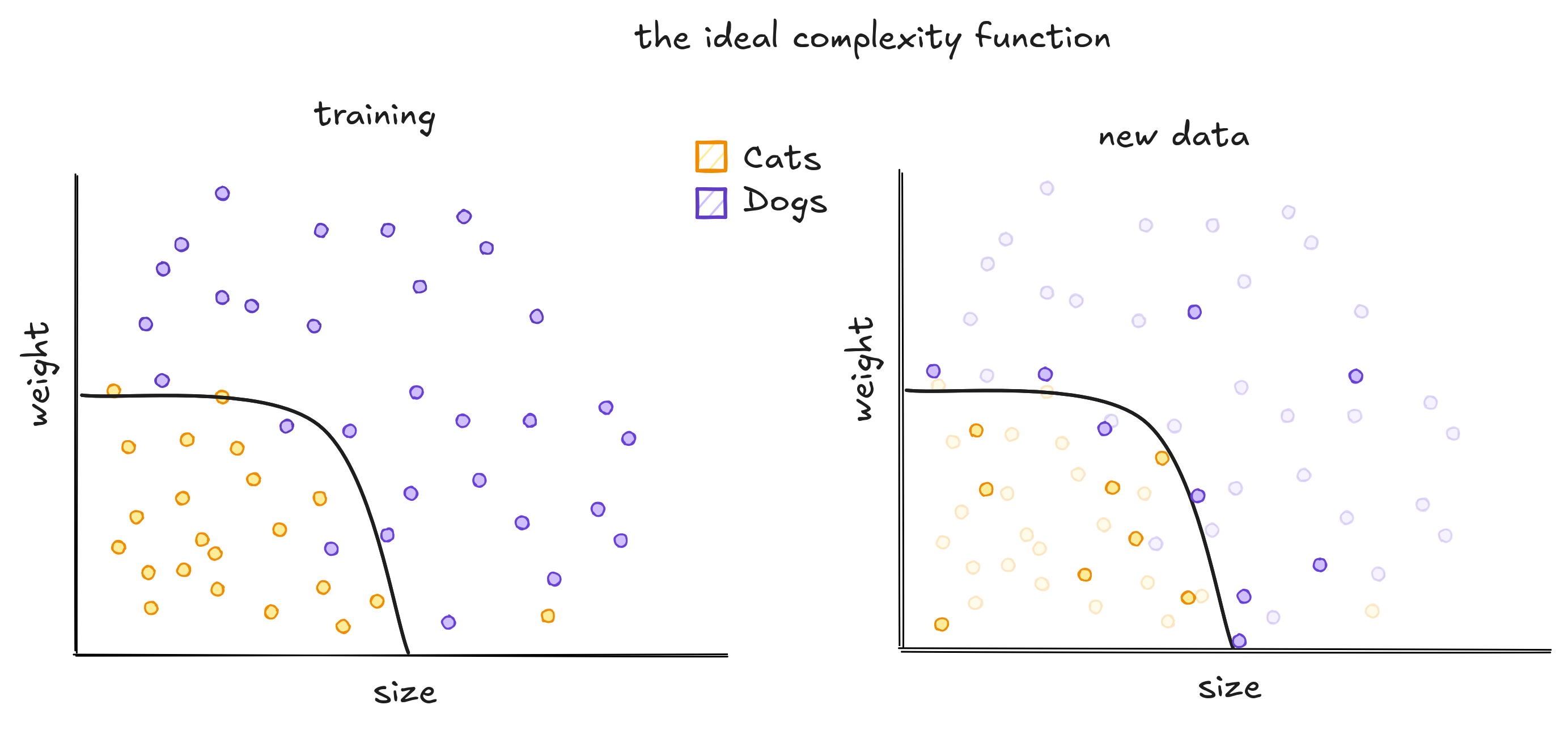
To classify these animals we can use Machine Learning. These models generalize from seeing some examples. Generalizing means that when presented a new animal, the model will be able to classify between cats and dogs. The same way a child see cats and learn what a cat is, computers see data and do the same. But choosing an model is not an easy task. We can use one line, lots of lines or even curves to separate dogs and cats.
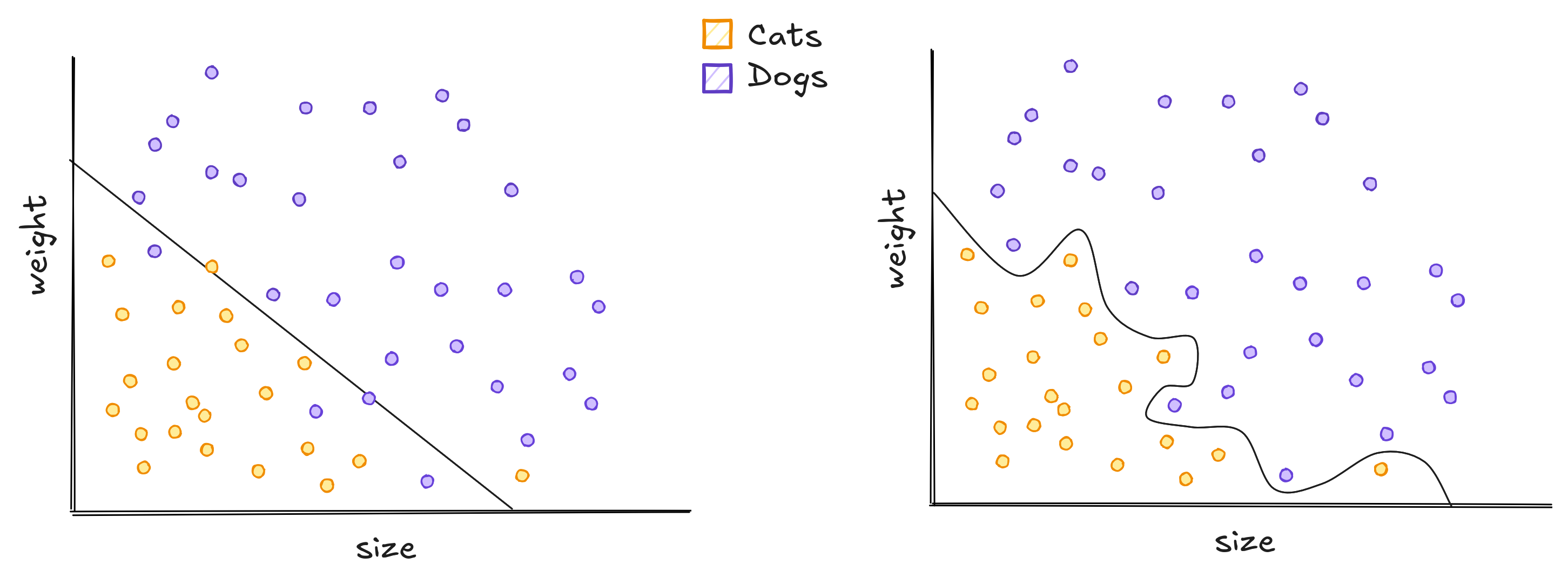
The traced curves are trained on the dataset to classify every new point below it as a cat, and every point above it as a dog. The line does not separate all dogs and cats correctly while the squigly curve separate all dogs and cats correctly.
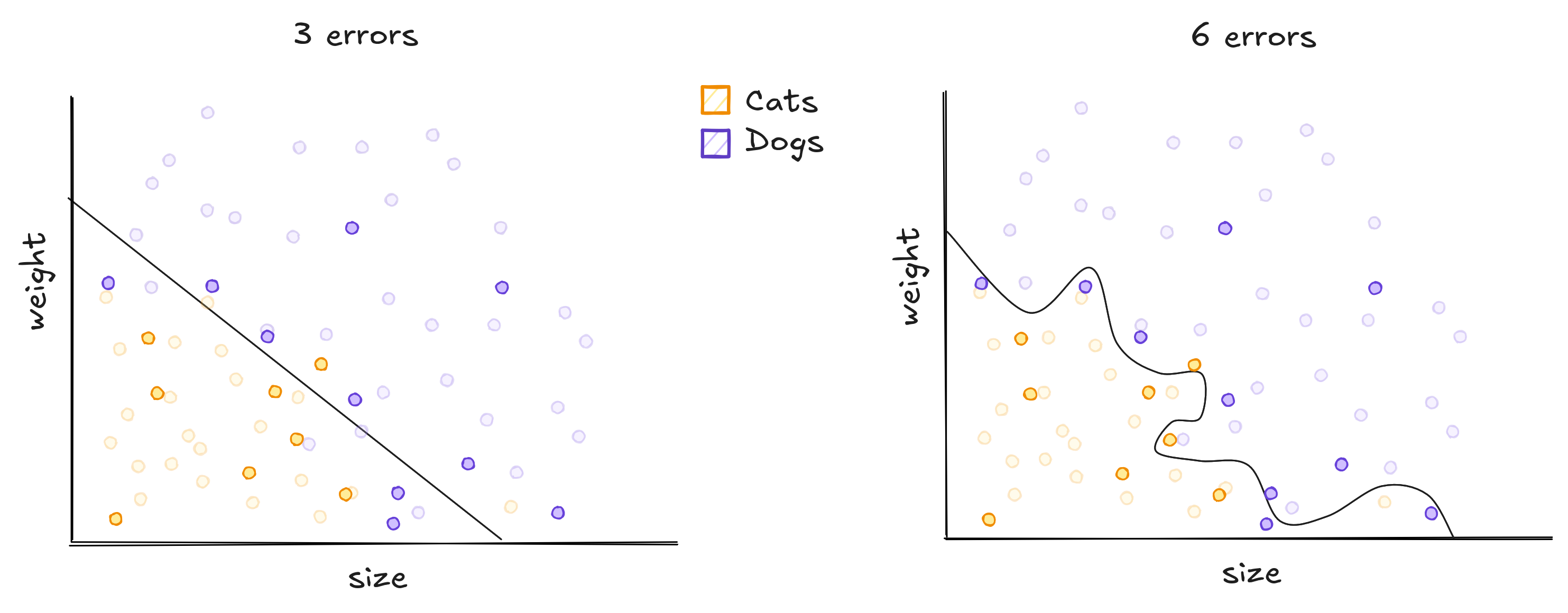
To compute the performance of an model, we count it's errors on the measures recorded. A well trained model should be able to classify animals it has never seen before correctly.
When unseen data is presented, the traced curves below perform differently. The line has some errors, while the curvy line performs poorly.
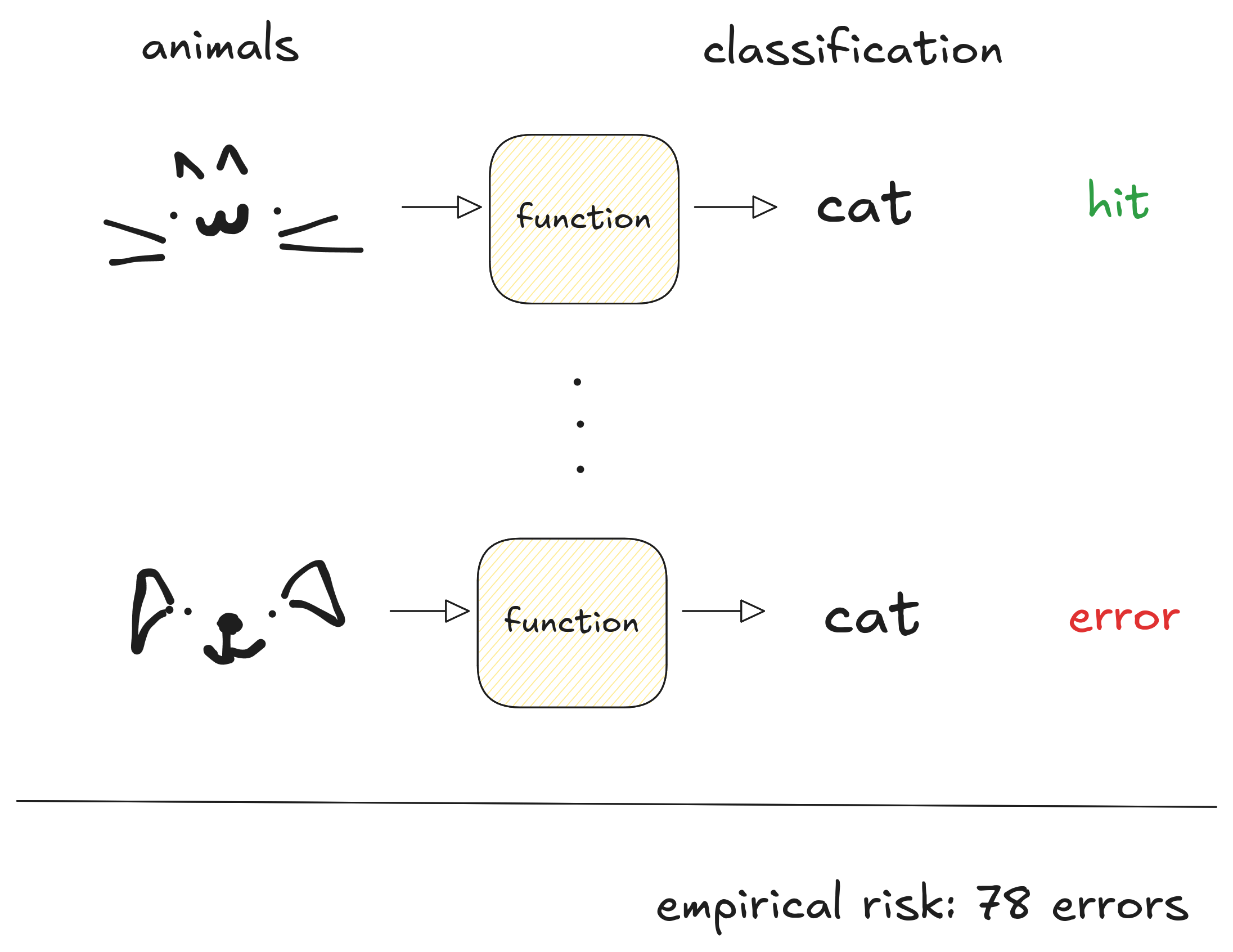
This task in Machine Learning is called classification, where the learned function outputs categories.
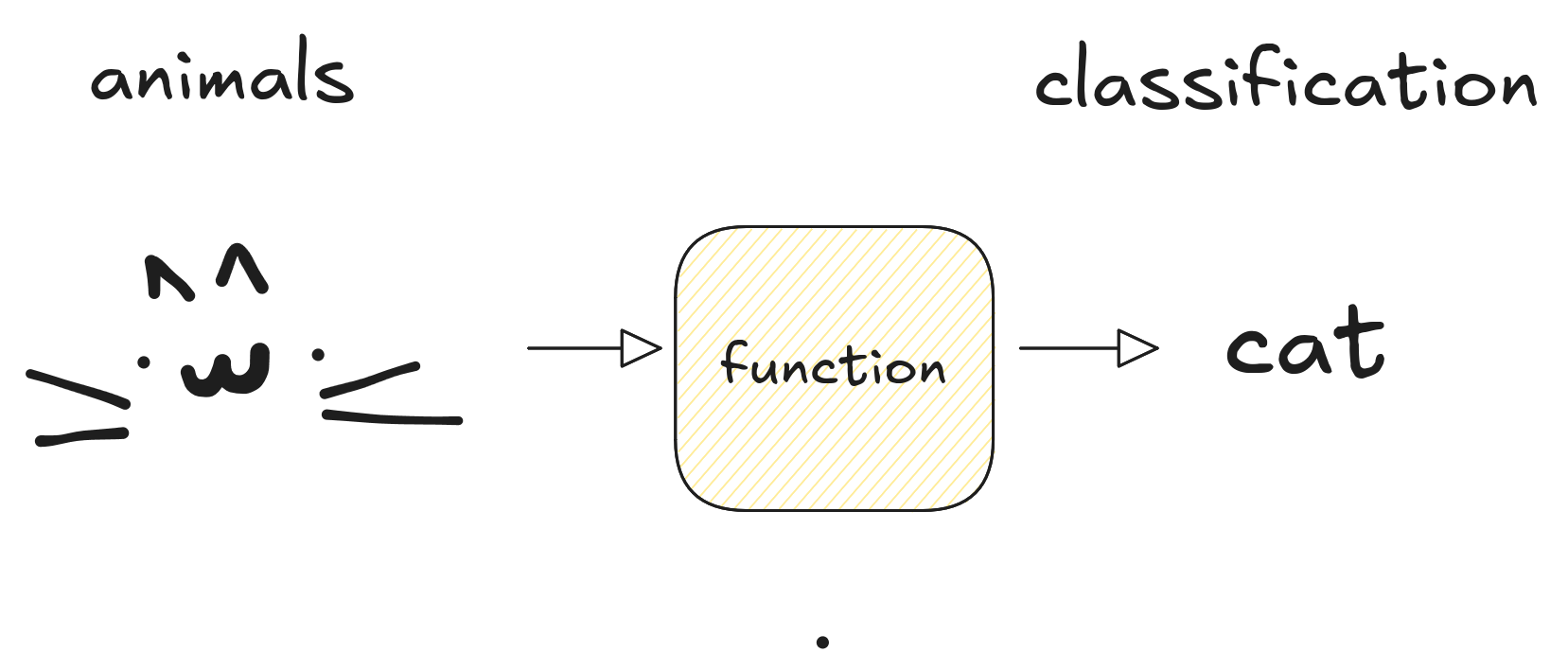
The model is just a function which takes examples of the input space - dogs and cats information - and return labels cat and dog whether it is a cat or a dog respectively.
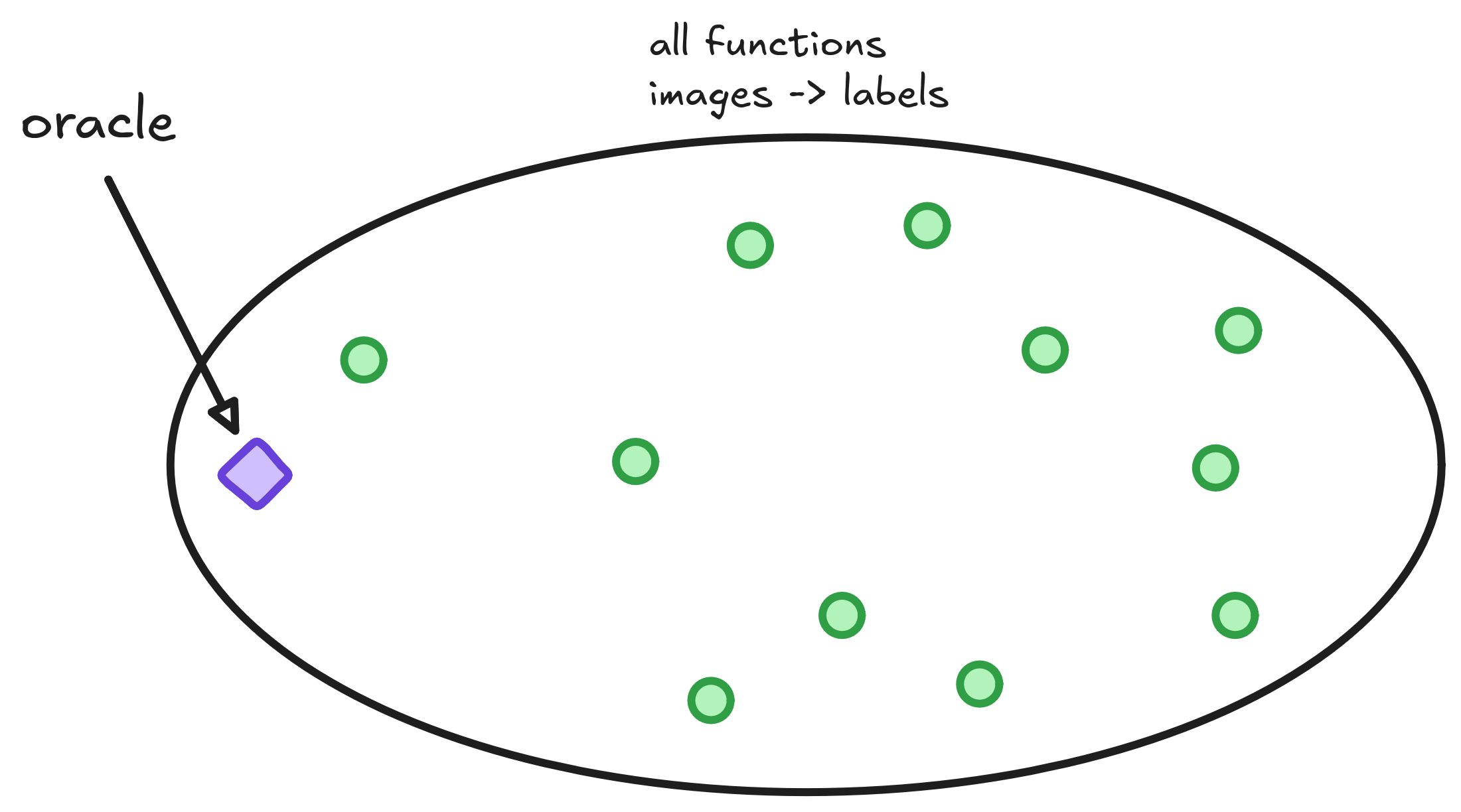
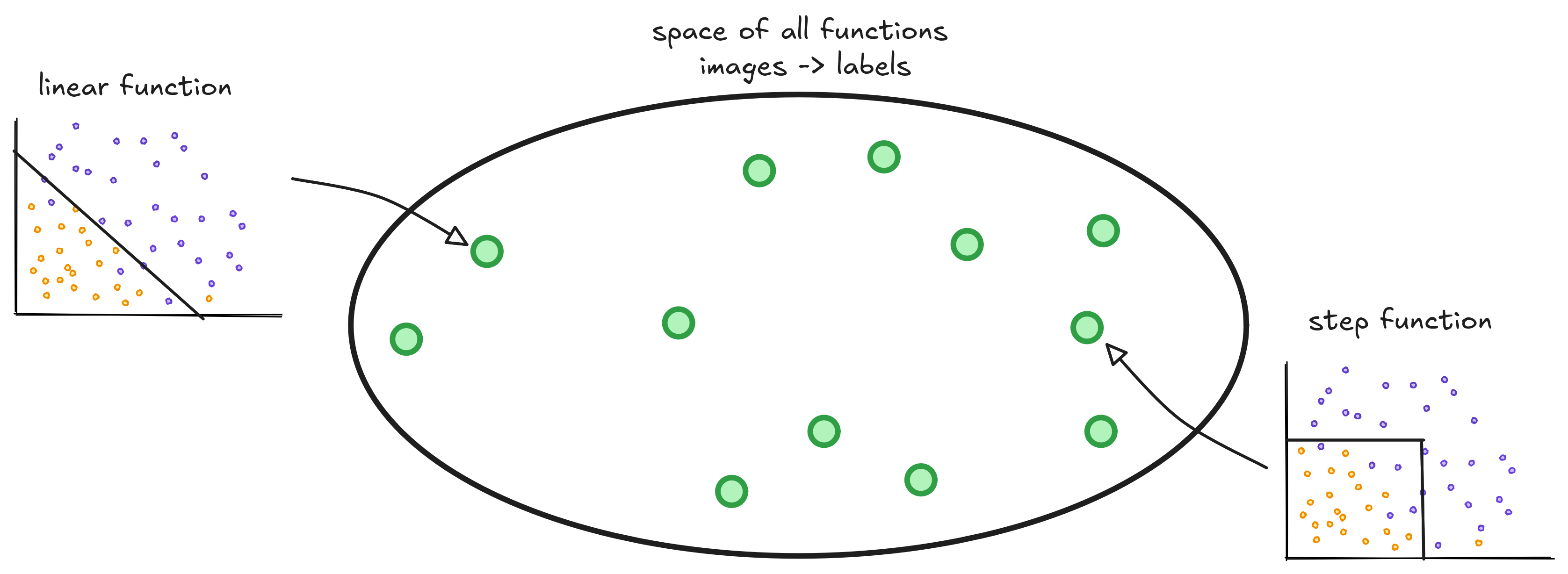
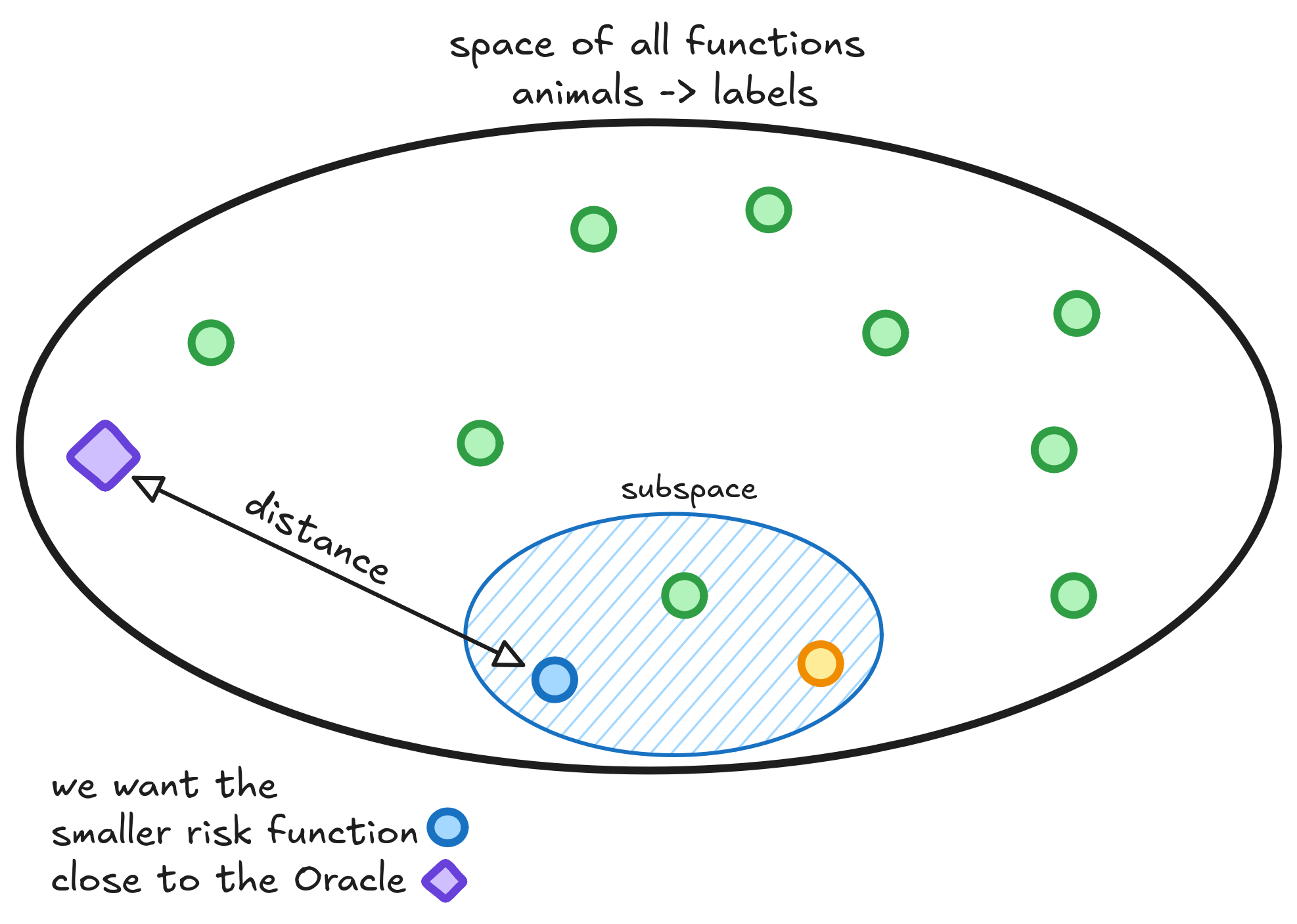
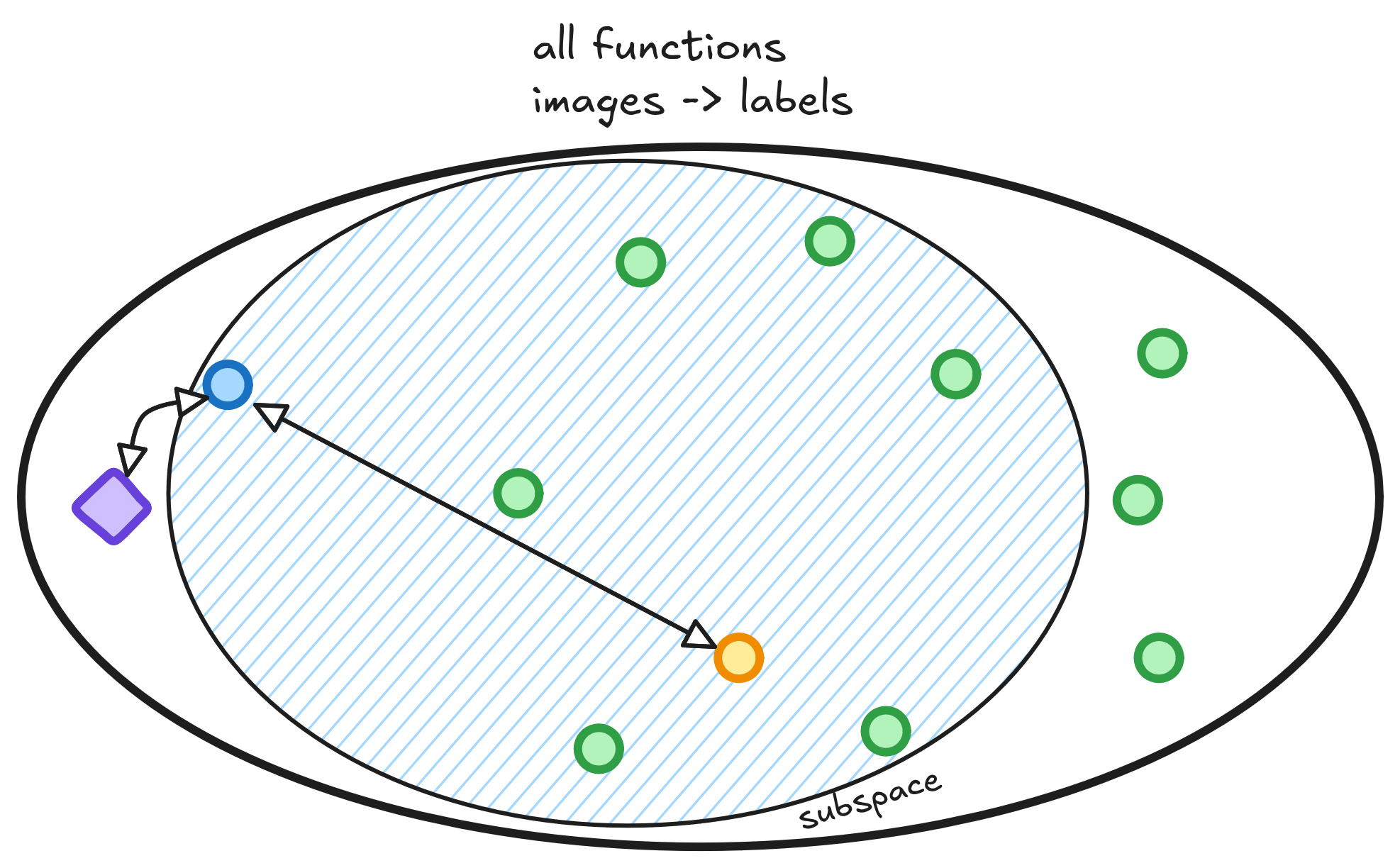
There exists lots of functions that receive an animal and return a {cat, dog} label. They can look like lines, curves or horrors behind our compreehension. We are searching for a classifier that can correctly distinguish between cats and dogs. Below I drew the space of all functions that take an animal and return a class. Each green point in this space is a function.
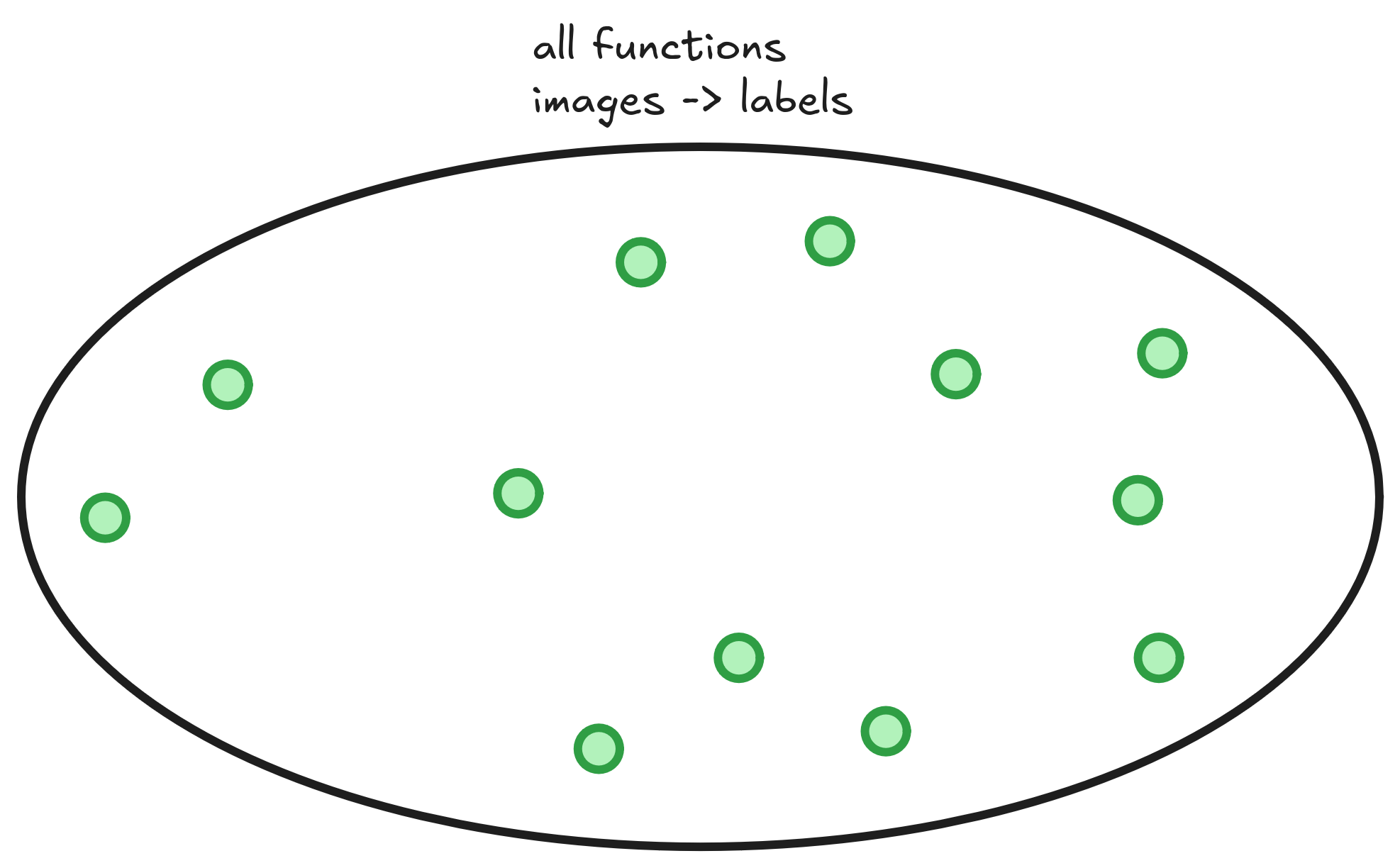
To measure how good each function is, we input information of all animals, compare with the labels and count how many times the function mislabeled the pet. This measure is called the function risk. The bigger the risk, the worse the function is, so we are searching for a small risk function.
That is a problem. To compute the true risk we need all dogs and cats information. All pets that lived, those which are alive right now and the ones which are still not born. Poetic - but unrealistic. An ideal model would need data from every pet, past, present and future, in order to classify with precision whether a pet is a dog or a cat. But we cannot have such big dataset. Instead, we use a smaller one - some dogs and cats from our neighboorhood we measured.
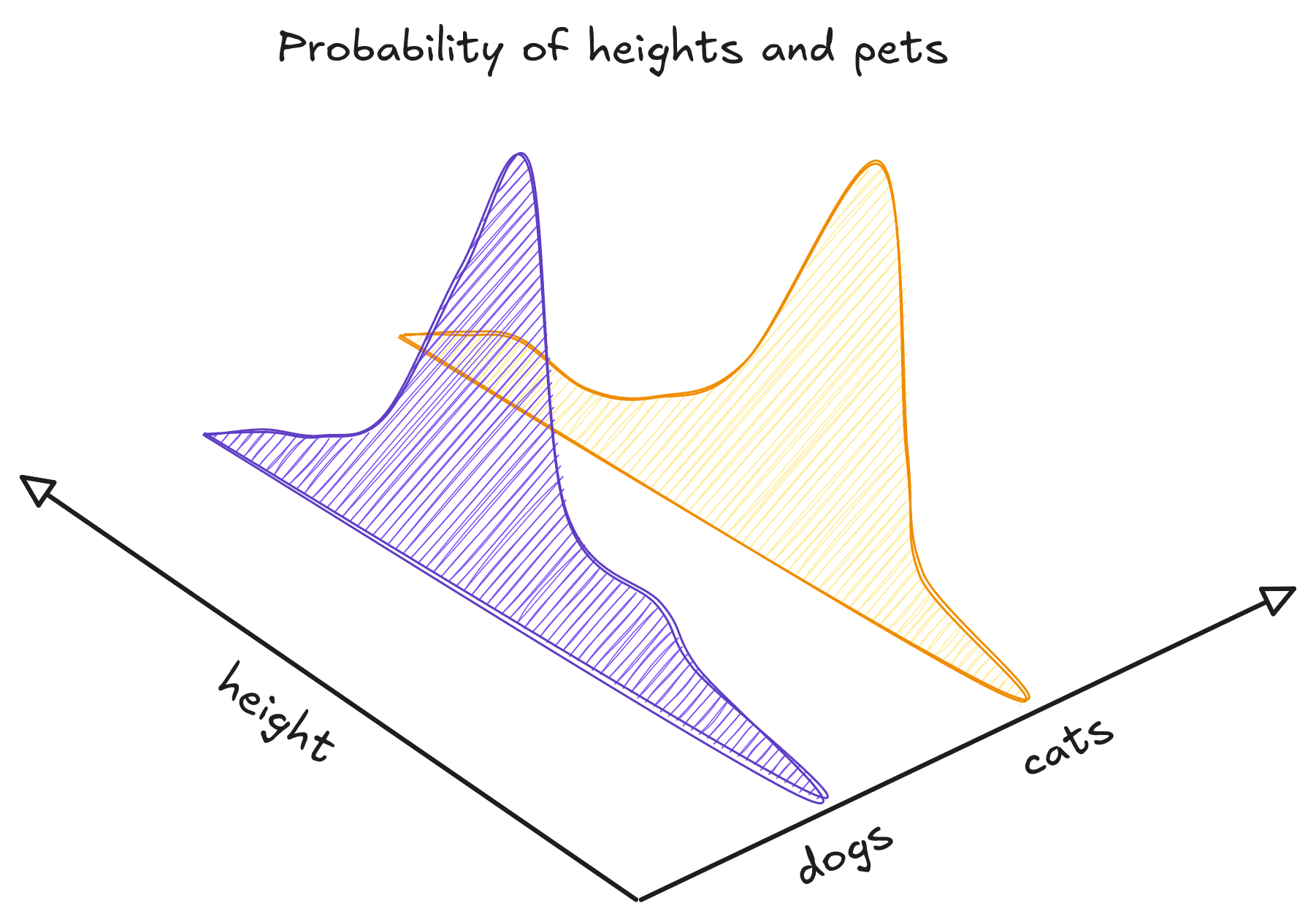
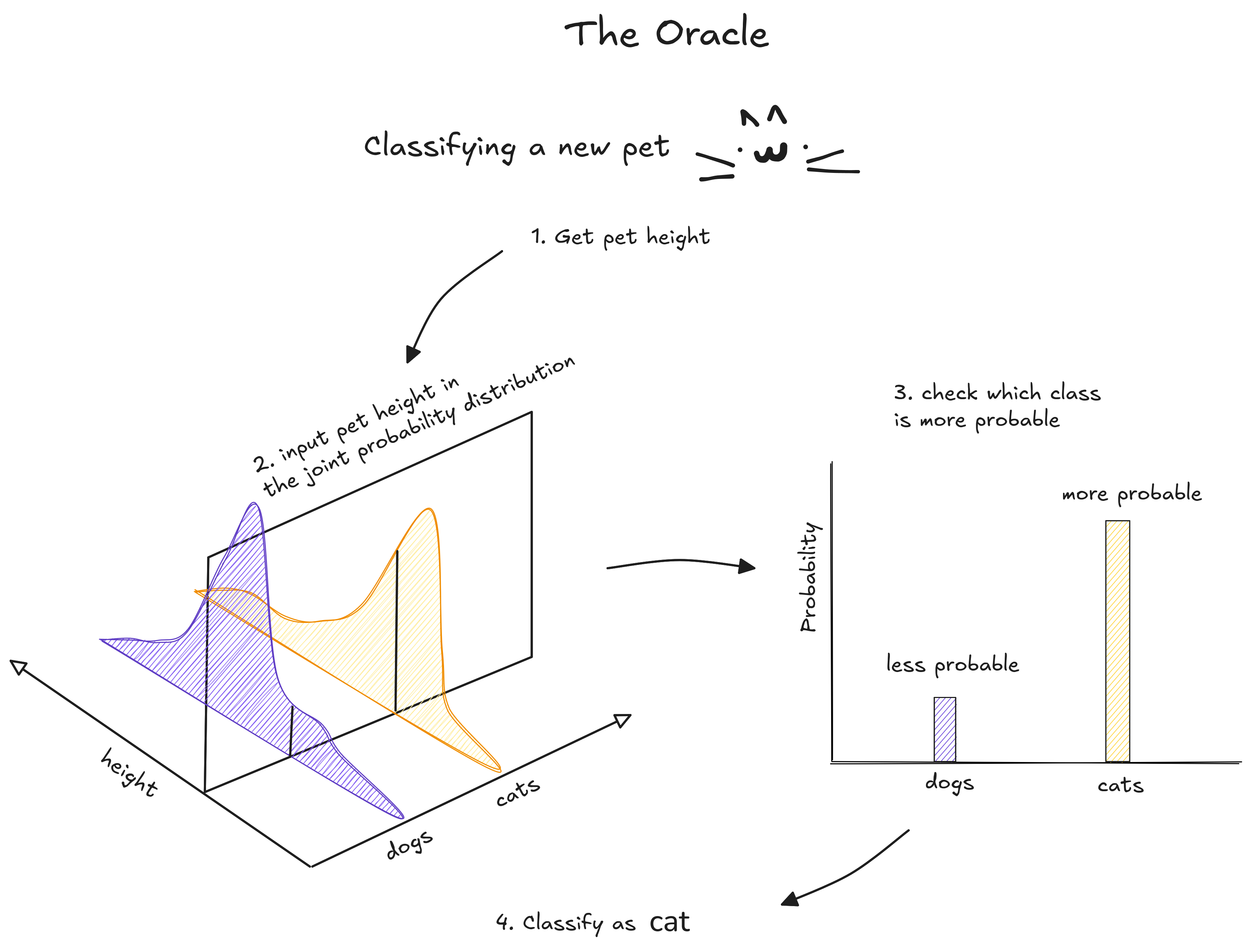
The set of all pets hides a probability function. We cannot see in more three dimensions, so to exemplify, consider only the height and class of the animals cat and dog. A point in the three dimensional graph has height, class and probability. It says which is the probability of finding a pet with this class (cat or dog) and this height.
By selecting a height value in this distribution, we obtain another distribution which tells us exactly whether an animal this tall has more chance of being a cat or a dog.
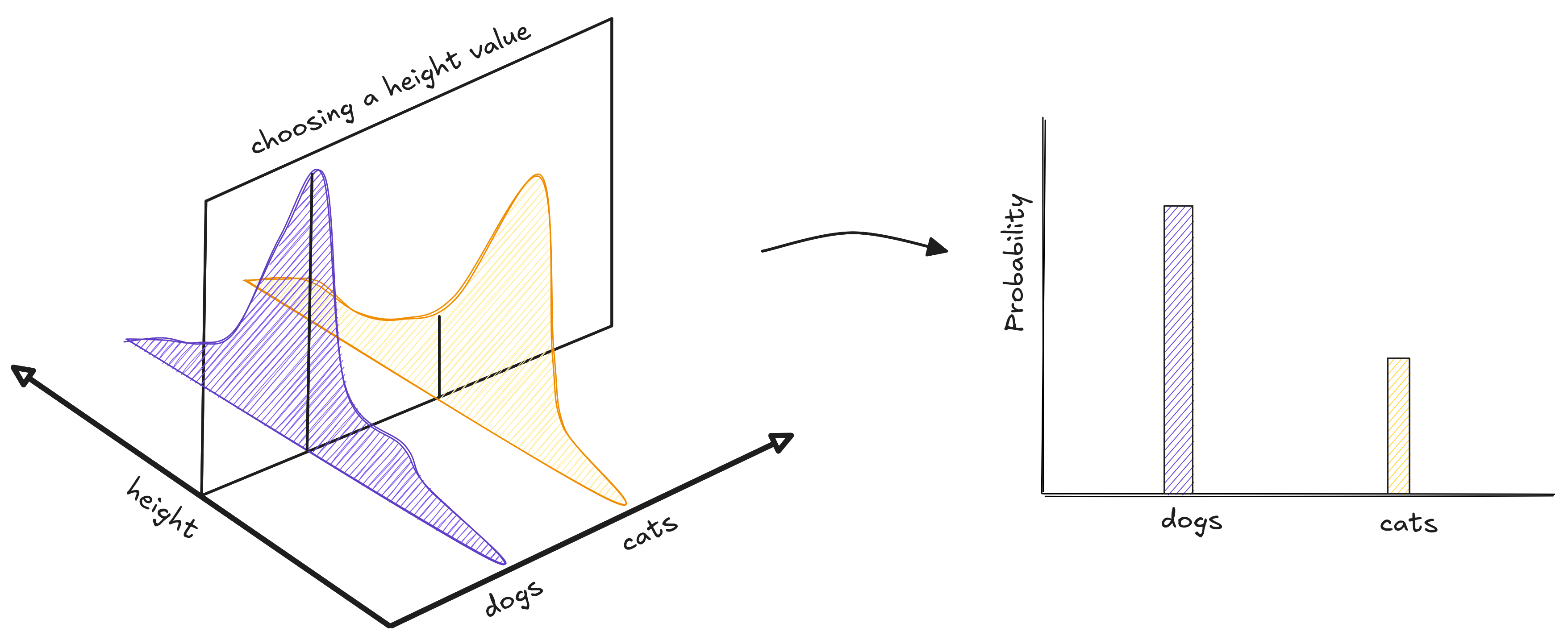
Unfortunately, we don't have acess to this distribution. If we had, we could skip the learning part. And since we don't have all images nor the data distribution, we cannot compute the real risk. Our only option is to use our dataset, a set of samples from the real distribution, to compute an approximation of the true risk named empirical risk.
Many functions exist - each with its own risk. Of the many functions that exist, one has the smallest possible risk. This magical function is sometimes called Oracle.
The Oracle wins because it cheats by consulting the probability distribution to classify an image. If the image has greater chance of being classified as dog, the Oracle classify as a dog. Otherwise, as a cat. No wonder why it is so good.
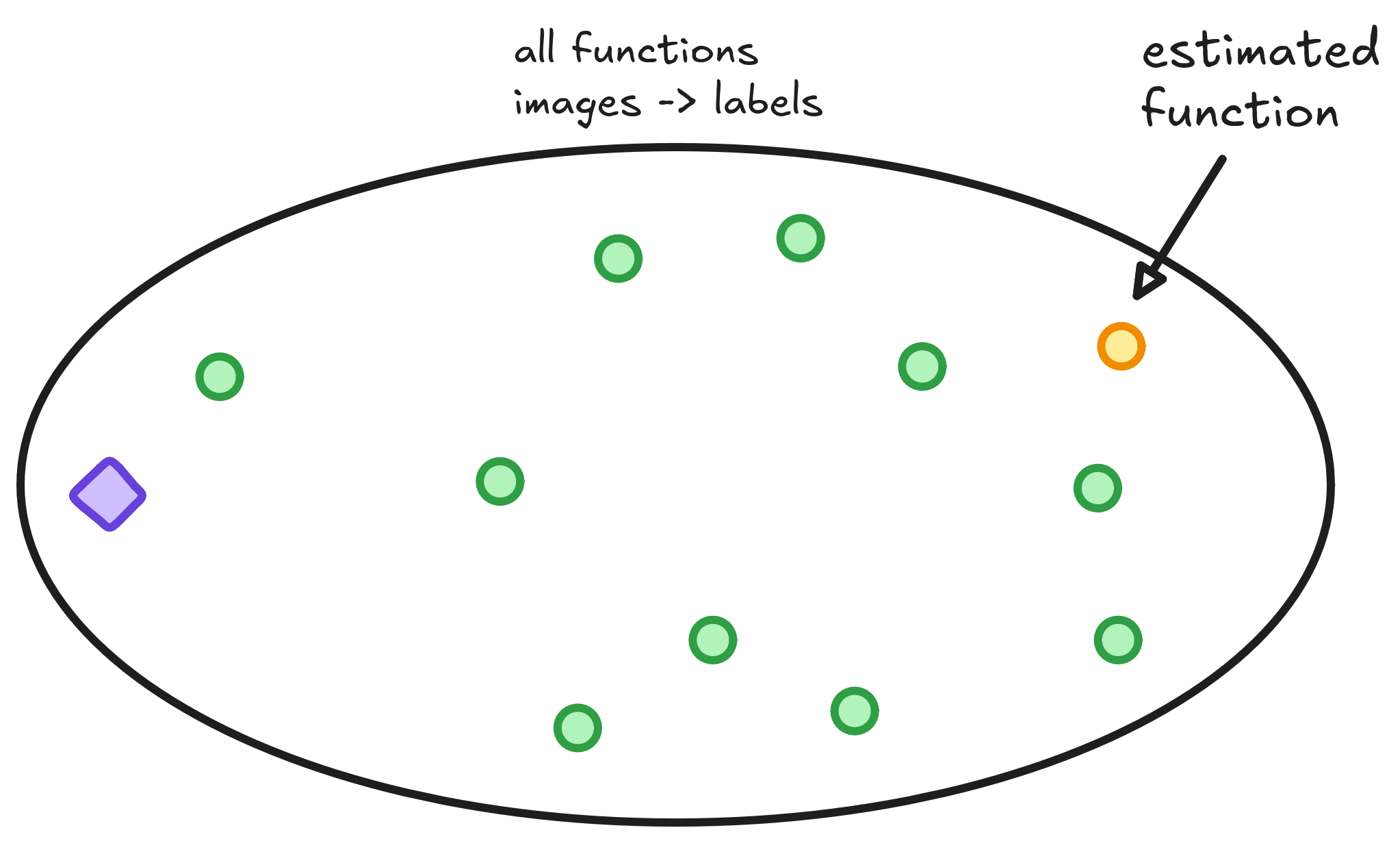
Our task as engineers and scientists is to get closer to the Oracle function as possible. Our best try is a function that lives happily in the space, trained on whatever dataset we found.
The space of functions that take pets and classify as cats or dogs is very diverse. Many functions - linear, quadratic, step functions, discontinuous and other ones - live there. All of them classify animals as cats and dogs.
Nested inside this vast space are subspaces - and each subspace contains a smaller portion of all functions. Some of these subspaces are bigger than the others. Take the quadratic space, a space where the quadratic functions live. Linear functions are a subset of quadratics where the quadratic term is zero. Thus, the quadratic functions space also contains the linear functions space.
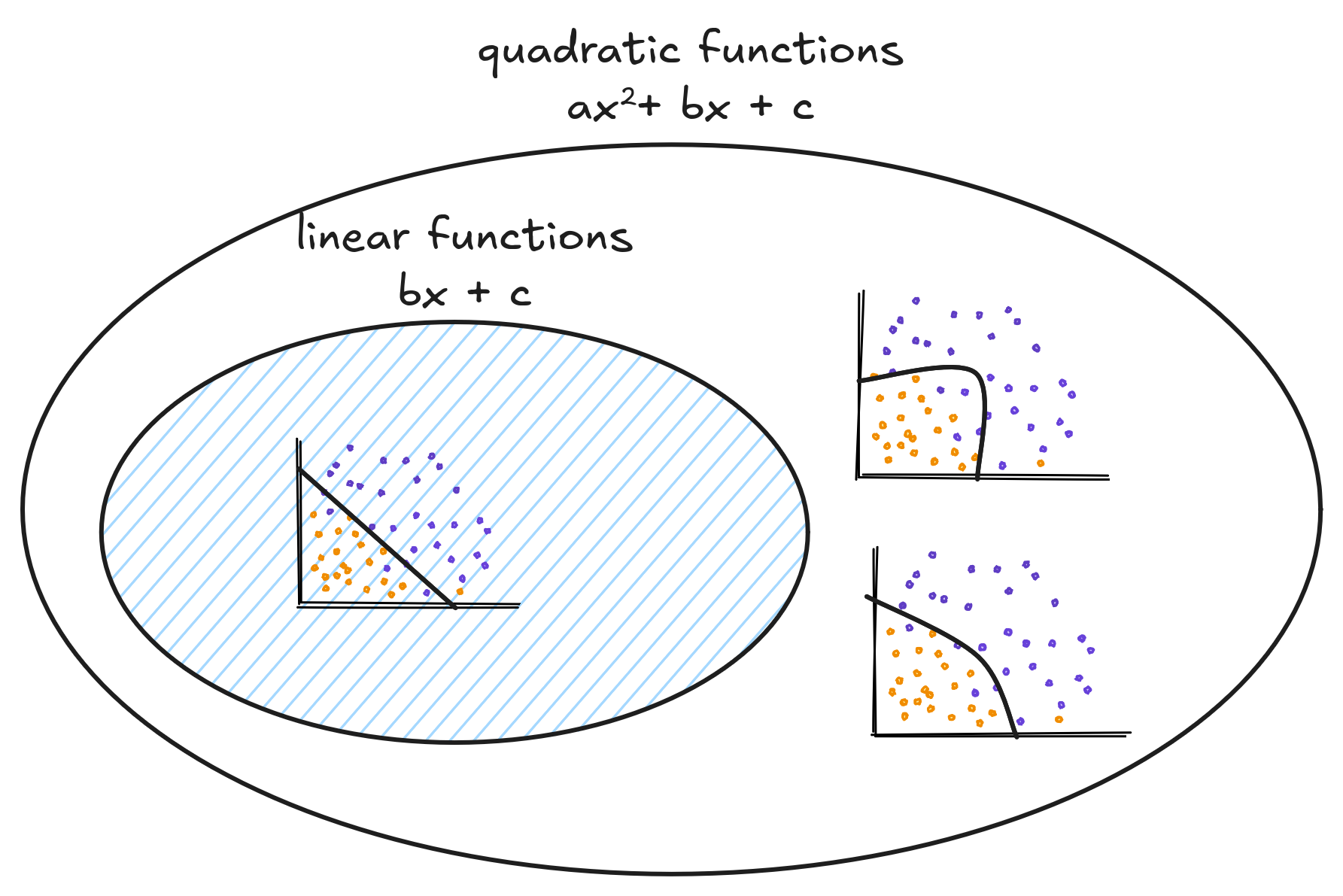
In Machine Learning, when choosing between Random Forests, Logistic Regressors or Neural Networks to classify a dataset, we also choose a subspace. If we choose a linear model, like Logistic Regression, we will use a function that lies on the linear functions subspace. Choosing a class of functions means instead of looking through the whole space of functions that take animals as inputs and classify them, we will search over the subspace.
The challenge is choosing which subspace to search.
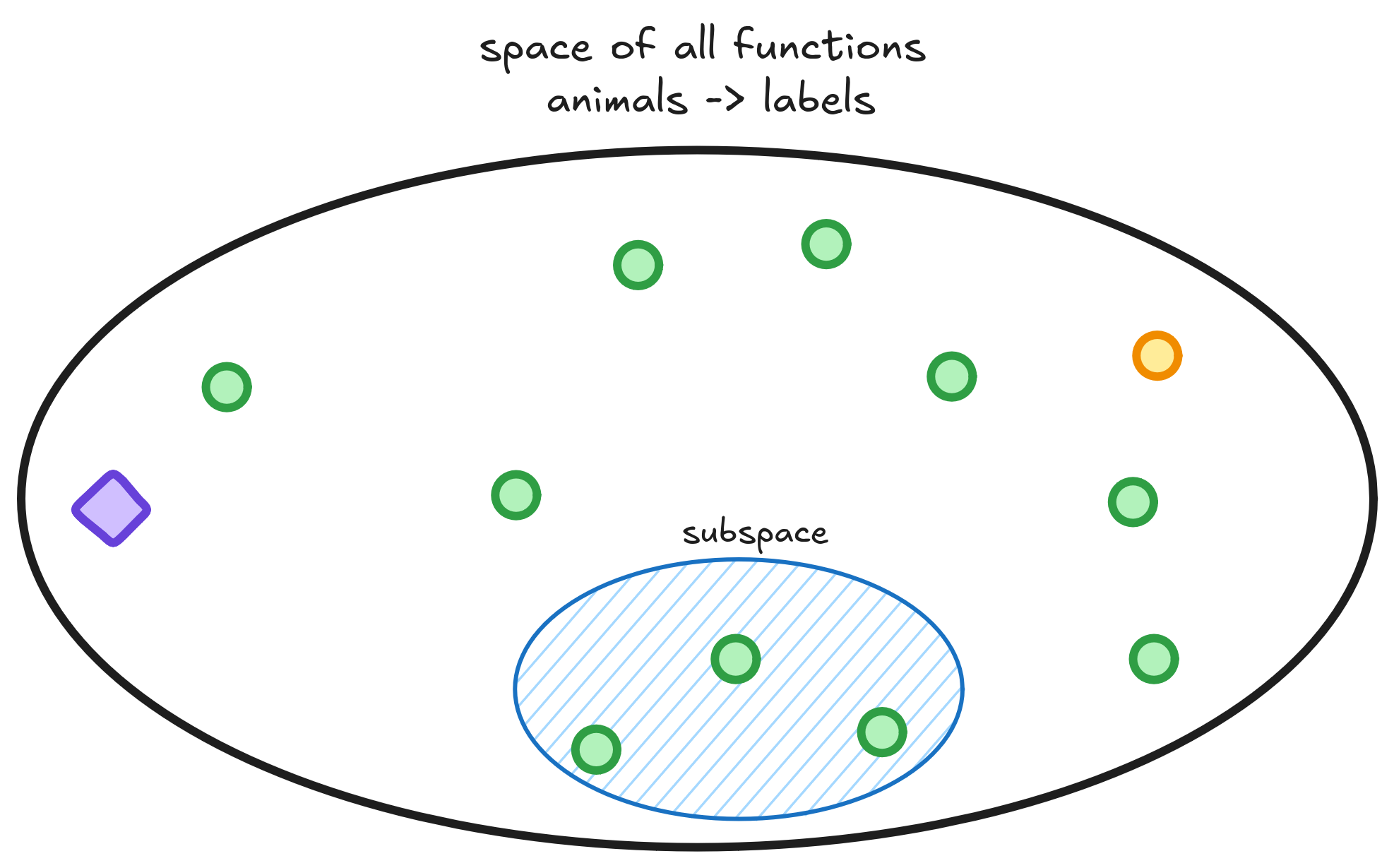
We have no clue whether the Oracle function lives or not in the subspace. The only confidence is that one function in this subspace has the smallest risk. During training, when the model learns to classify labels based on images from the dataset, we aim to find this lowest-risk function. The best we can do is learn a function as close as possible to it using our dataset.
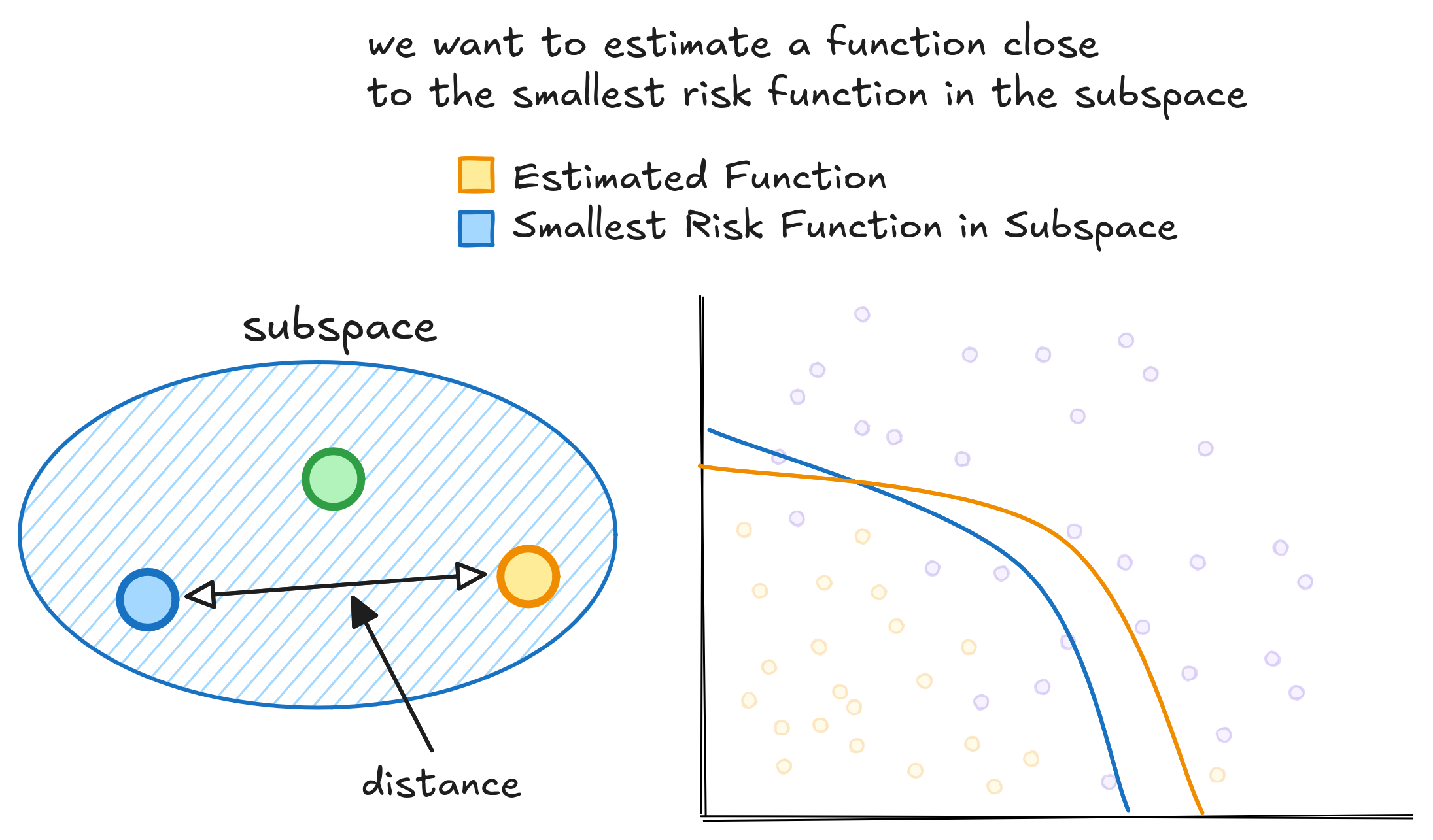
We also need to measure how well functions in our subspace can approximate any function in the full space. Thus, we shall also minimize the distance between the best function in the subspace and the Oracle.
At this point we have a more precise view of the learning problem. There are functions that take animals images and return labels; we approximated each function true risk using the empirical risk. An ultimately good function - the Oracle - exists. And to learn we should choose a class of functions. We are asked, what class of functions shall we use?
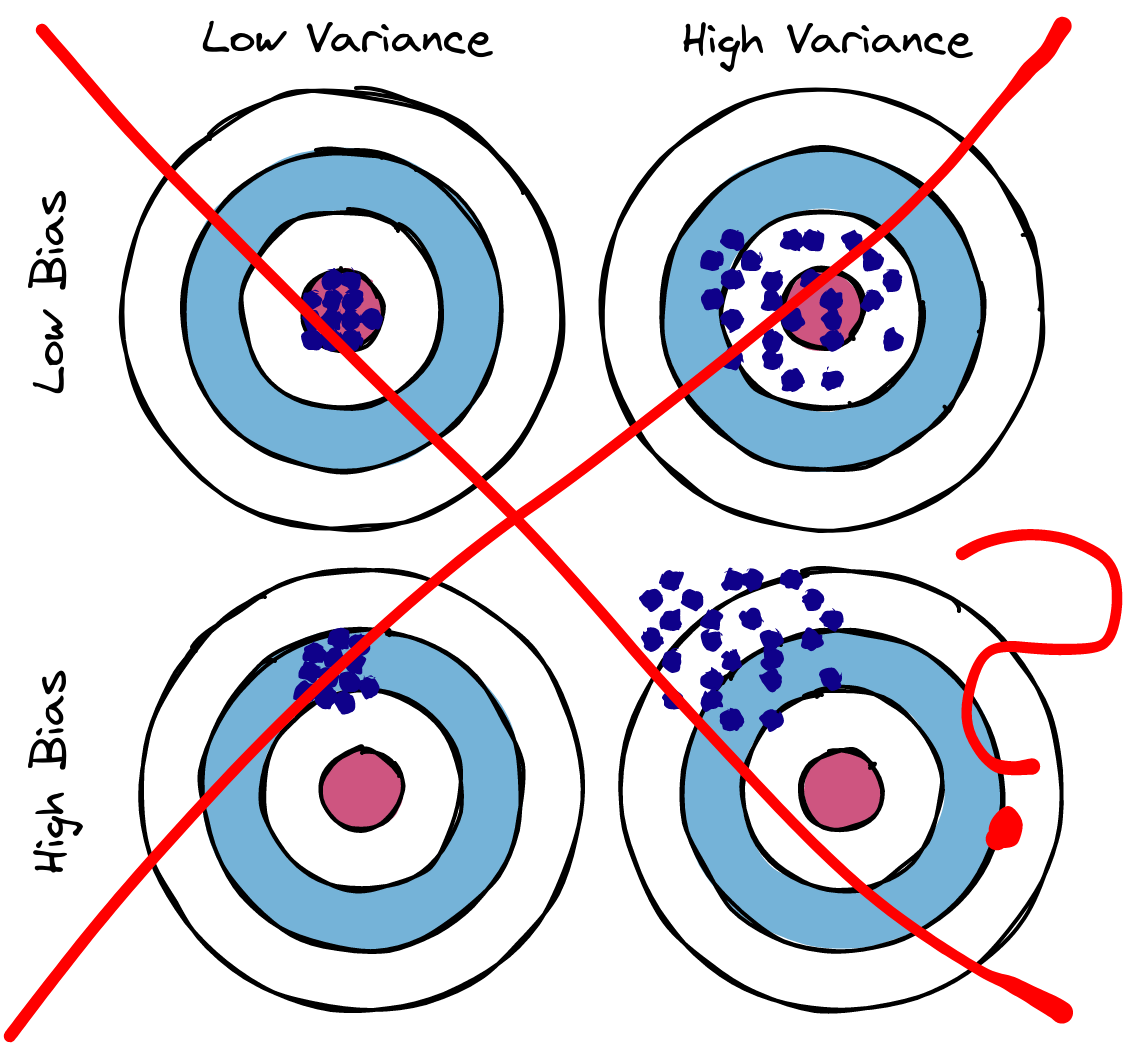
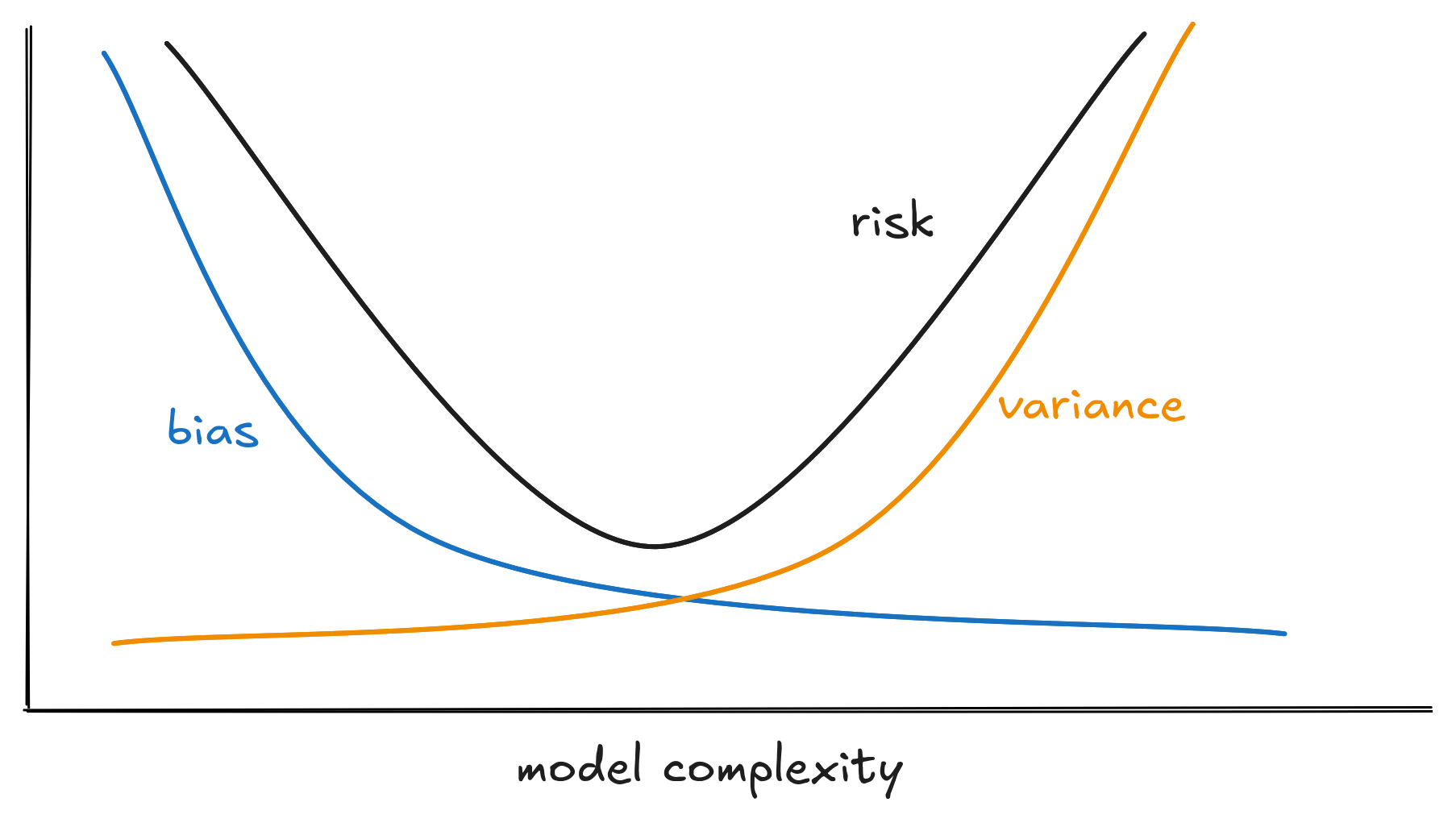
In one form or another, this problem has long worried engineers and scientists. This is the widely known problem in statistics entitled bias-variance tradeoff.
If we choose to separate classes using a line, every relation we ever find would be linear. But this would not come from data. Instead, it will be a bias imposed by us. It will have high risk, making some mistakes and will not correctly separate the animals.
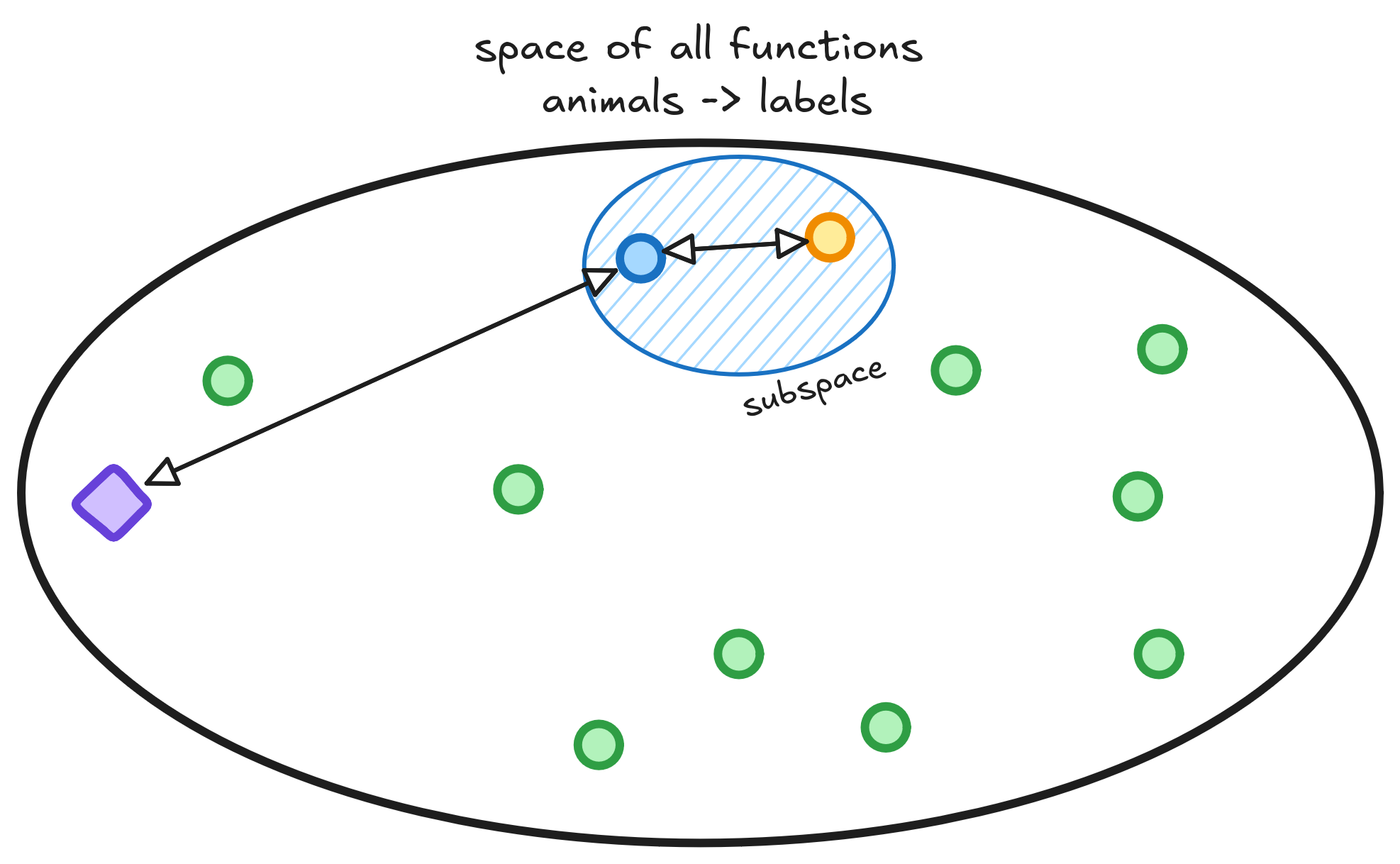
In our example, tracing a line to classify dogs and cats is choosing the reduced subspace of linear functions to search on. A small space means the distance between the better function we can achieve and the Oracle will be very big. Eventhough, it's easier to find a good estimate for the function inside the subspace since it's too small.
Conversely, if we choose a very curvy line to separate each dataset, we would always be able to separate pets from the dataset correctly. However, the model would fluctuate wildly, depending on how accurate our dataset reflects the real world.
In a large subspace, the best achievable function is close to the Oracle (which might even reside there). Although, an overly large subspace makes the model sensitive to dataset changes. We could find a function with big risk, small risk or medium risk - the model would suffer from large variance.
In Machine Learning, it's common to explain this duality using the terms underfitting and overfitting. When the model suffers with high variance, we say it overfitted. Elseway, models with high bias suffer from underfitting. The ideal model - the one with lowest risk - lies somewhere between those two worlds.
To classify correctly the pets in our dataset, a quadratic function would be ideal. Not simple as a line, nor too complicated as the high degree polynomial.
Thus, we find the perfectly equilibrated subspace to estimate our function. But the journey of a scientist extends beyond quadratics. The toolbox of a good one should include regularizers.