
This changelog is the most important one we've shipped so far - that's why it took more than two weeks for us to post it.
In these last few weeks, we've completely rebuilt our editor so it's more understandable, more reliable, and more flexible.
We've also introduced environment variables, which allow you to store information like settings, API keys, and database credentials securely. Then, you can reference these variables in your code without exposing them.
Our new editor and a ton of related improvements
Before this change, our editor was more unstable than we'd like. Sometimes the editor would show different states than what was happening in the back-end. Refreshing the page also caused the editor to lose part of its state, like which blocks were running, or undergoing AI suggestions. All these issues are now gone, and we're glad to have received lots of positive feedback about the new editor.
The new editor we're rolling out for everyone today is more reliable, more flexible, and more understandable. We now manage and reconcile every single piece of state in the back-end. Consequently, the editor's state will be consistent across refreshes, and for all users and devices.
This change also comes with a bunch of very important improvements. Here are some of them:
- When using data apps, each viewer will have their own state. That means that if you're viewing a document and someone else is viewing it at the same time, you won't see each other's inputs and results.
- The "Run All" button now shows the number of blocks that have already run, and how many are left.
- We explicitly display enqueueing and running states for each block.
- When a scheduled run is happening as you view a document, you'll see its results in real time.
- You can now duplicate whole blocks or individual tabs by clicking the drag-handle menu on the left side of the block.
- You can run an entire block from left to right by clicking the "Run all tabs" button that appears within the drag-handle menu for multi-tab blocks.
- Data apps will only be updated when you click the "Update Data App" button. This way, you can make multiple changes to the inputs and dropdown fields of a data app and only publish them when you're ready.
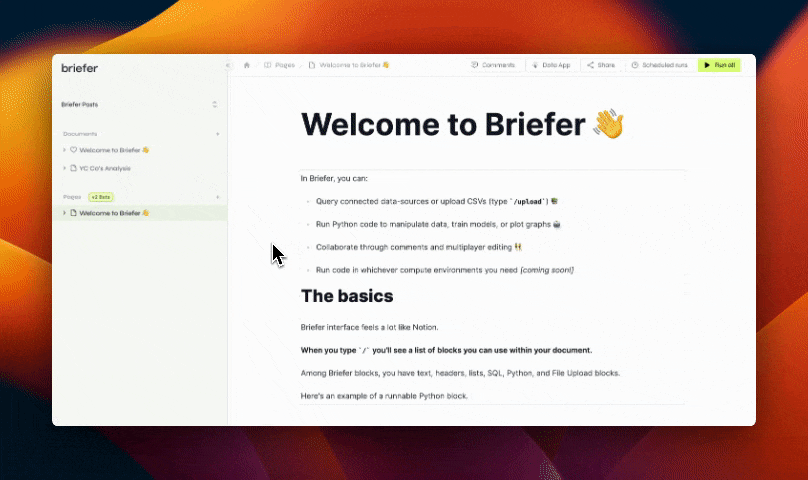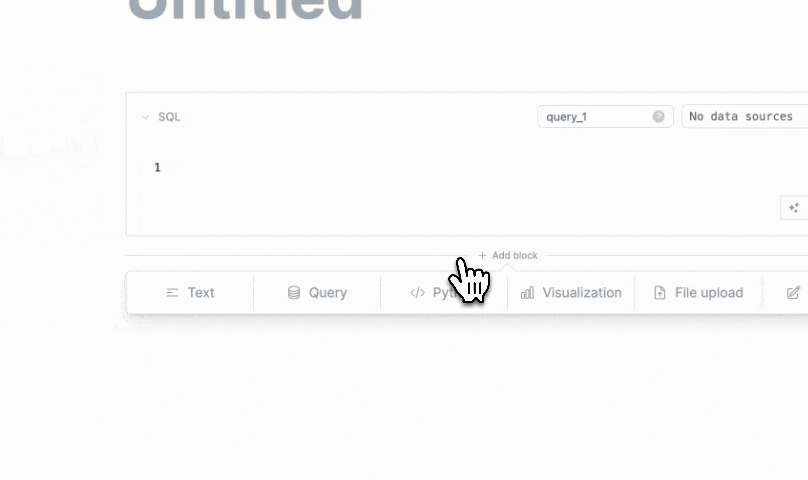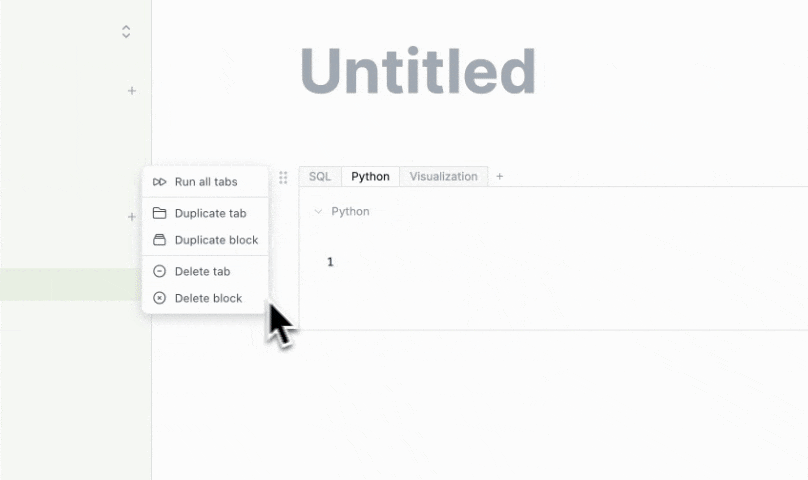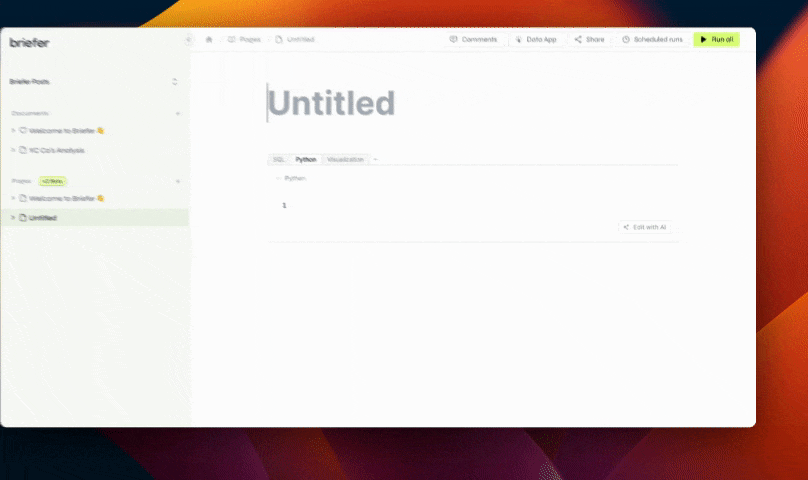
- Adding new blocks is now more intuitive. You can now add blocks by clicking the "+" button that appears when you hover over gaps between blocks.
- You can now group all types of blocks, not only Python, SQL, and Visualizations.
- If you create a new dataframe that only exists in a Python block, it will be immediately available within visualization blocks.
- You don't have to uncollapse a block to run it anymore. You can now run a block by clicking the "Run" button that appears when you hover over the block.
- We'll now persist the open/close state of the document tree on the left as you navigate between documents. This way, you won't have to keep opening nested folders every time you navigate to a different document.
Environment variables and how to use them
Environment variables are a way to store information like API keys, database credentials, and other settings securely. That way, you can then reference these variables in your code without exposing them to viewers.
These environment variables are useful when you want your Python blocks to perform authenticated API requests, like when doing writebacks to your database, for example.
To create an environment variable, click the "Environment Variables" button on the bottom-left corner of the editor. Then, click the button at the bottom of the list to add a new variable. Once you're done, click the save button and restart your environment for the new environment variables to be available.
You can then reference this variable in your Python code by using the os.getenv function.
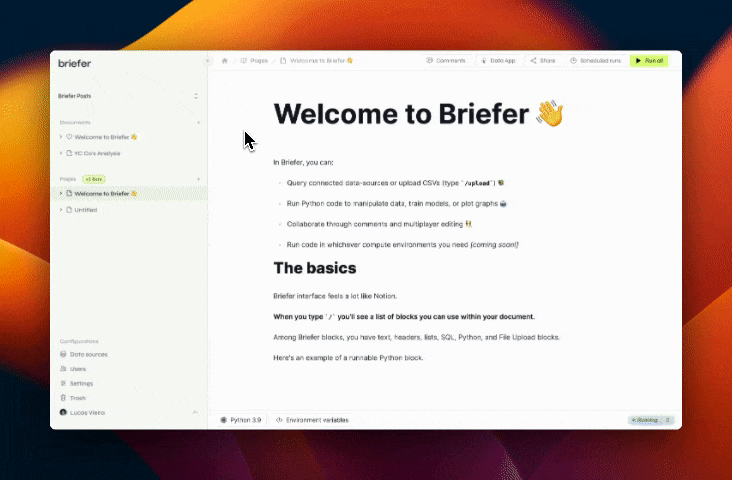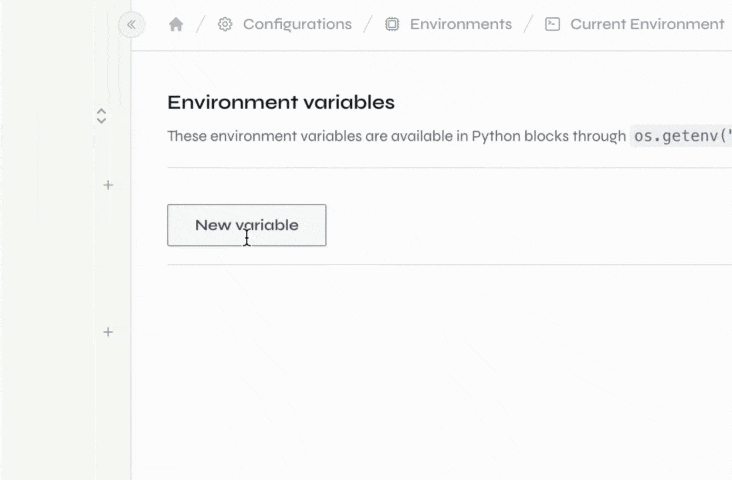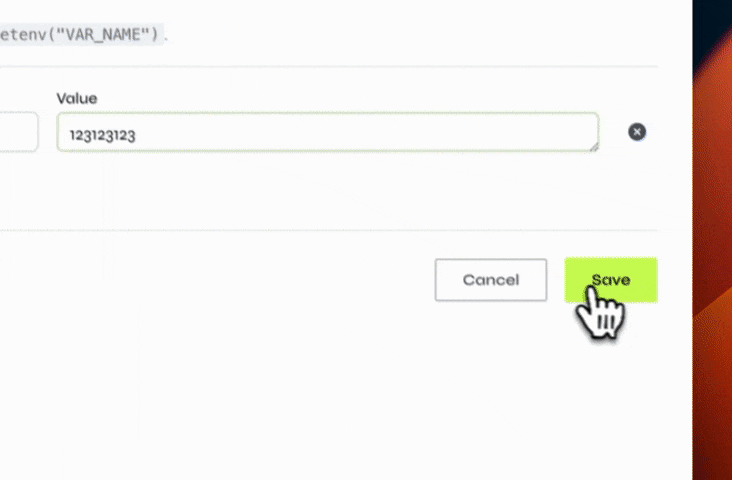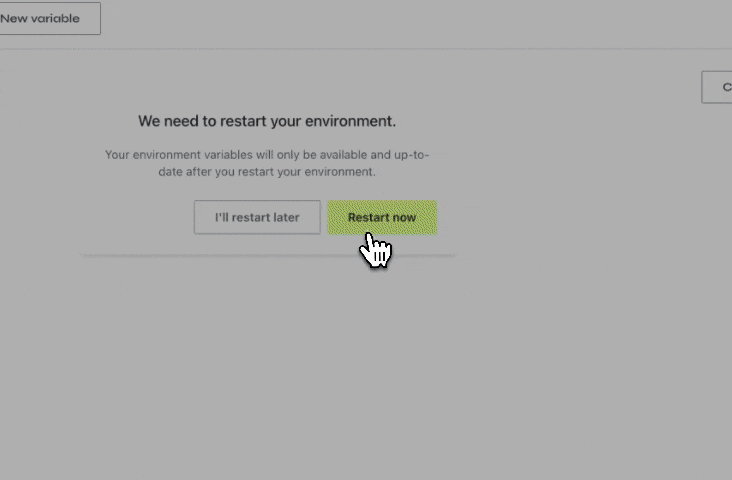
By the way, we also added a button on the bottom right of the editor so you can restart your environment manually if you need that.
What's next?
We know it's been somewhat annoying to lose your in-memory state when your environment restarts. We're working on a way to automatically re-run dependencies or persist this state across restarts, so you won't lose your dataframes, variables, and other in-memory state when your environment restarts.
Expect that by the next changelog.