
Modern data engineering workflows turn chaotic pipelines into cohesive systems. Without them, teams find themselves tangled in brittle scripts, chasing mysterious data bugs, and responding to yet another "why is this dashboard blank?" message at midnight. This post unpacks how to design workflows that are reliable, maintainable, and most importantly, give your team some peace of mind.
Why data engineering workflows matter
The explosion of data sources, formats, and consumer expectations has made informal, ad-hoc pipelines an unsustainable strategy. Gone are the days when nightly ETL jobs into a single data warehouse sufficed. Today’s workflows must contend with SaaS apps, semi-structured data, real-time streaming, and machine learning pipelinesm, all under pressure to deliver accurate insights rapidly.
A well-designed workflow doesn’t just move data from one place to another; it defines the velocity, reliability, and ultimately the credibility of data-driven decisions within the organization. Without structure, you’re not running a workflow: you’re automating chaos.
Anatomy of a modern data engineering workflow
Ingestion: where the battle begins
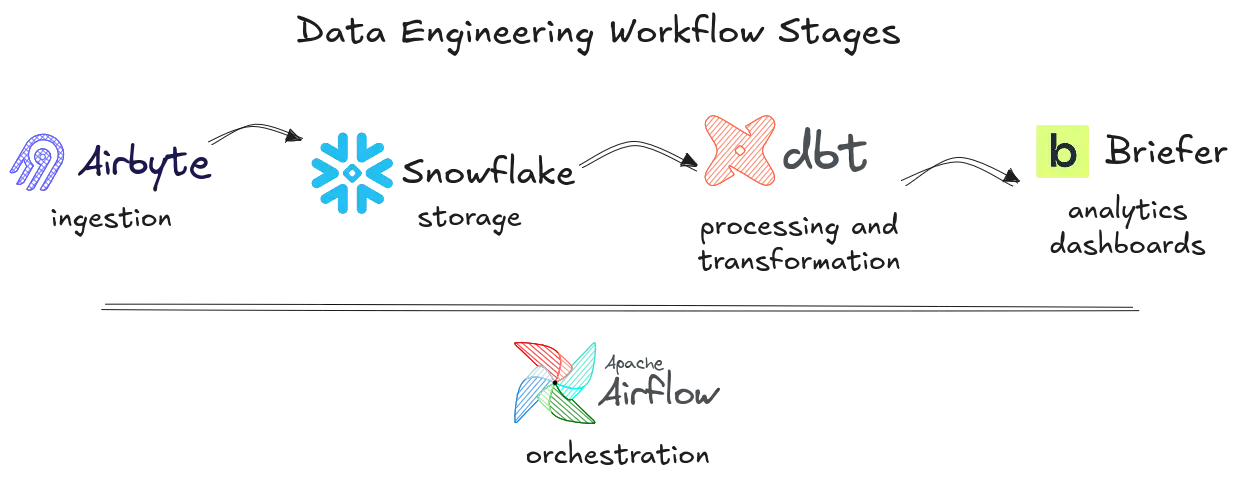
At the core of this structure lies ingestion, the process of getting data from various systems into a centralized environment. This is where the battle against entropy begins. For many teams, managed ingestion tools offer the most pragmatic path forward. Airbyte, for instance, provides an open-source alternative that balances flexibility with ease of use. Its pre-built connectors and modular design let teams standardize ingestion without locking into a proprietary system.
While some organizations turn to streaming platforms like Apache Kafka for low-latency event processing, it’s worth pausing to ask whether you really need to operate such heavyweight infrastructure. In most cases, simpler batch ingestion suffices and keeps complexity in check.
Storage: where data lives
Once ingested, data needs a reliable and scalable home. This is where the modern cloud data warehouse steps in, offering separation of storage and compute, automated scaling, and SQL compatibility for broad accessibility. Snowflake exemplifies this new paradigm, making it possible for multiple teams to work concurrently without bottlenecks or performance degradation.
Google BigQuery offers a similar model, but the choice between them often comes down to cloud alignment and cost structures. Regardless of the platform, the goal remains the same: store raw and transformed data in a way that supports both analytical flexibility and operational efficiency.
Transformation: unlocking analytical value
With data securely stored, transformation becomes the next crucial phase, arguably where the real analytical value is unlocked. Historically, transformations occurred before loading, but modern workflows embrace ELT, performing transformations inside the warehouse itself.
This shift has propelled tools like dbt to the forefront. dbt enables modular, version-controlled SQL transformations that are rigorously tested and automatically documented. By promoting a software engineering approach to data modeling, dbt reduces the risk of rogue SQL proliferating across the organization, ensuring transformations are both reproducible and trustworthy.
For teams dealing with truly massive datasets, distributed processing frameworks like Apache Spark still hold relevance, but they introduce a layer of operational overhead that is often avoidable for most analytics workflows.
Orchestration: keeping it all on track
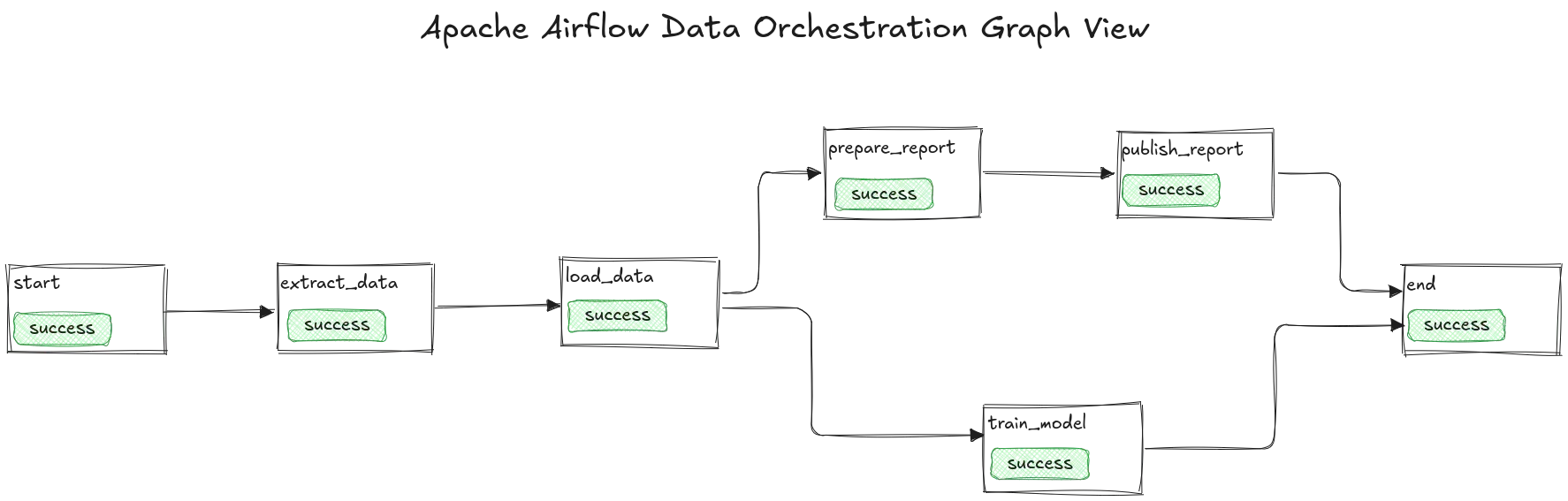
As transformations grow in complexity and interdependence, orchestration emerges as the unsung hero of the workflow. Orchestration ensures that tasks execute in the right order, with dependencies managed, failures retried, and workflows monitored.
Apache Airflow has become the default solution for this, providing a DAG-based interface that can model complex workflows across diverse systems. While its verbosity and sometimes finicky configuration are common gripes, Airflow’s flexibility keeps it firmly entrenched in data engineering stacks.
Newer contenders like Dagster promise improved developer experience and type safety, but broad adoption is still catching up. Regardless of the orchestration tool, the goal is consistent: prevent your workflow from becoming an untraceable spaghetti mess of cron jobs and manual triggers.
Delivery: getting data to the people
The final mile of the workflow is where data is delivered to those who need it most. This is no longer limited to dashboards and reports but increasingly involves feeding data back into operational systems, informing marketing campaigns, personalization engines, and customer support tools.
Reverse ETL platforms like Hightouch make this seamless by syncing data from the warehouse to external applications. However, the core of delivery for most organizations remains business intelligence and analytics.
Here, Briefer offers a powerful solution: a modern data workspace with a built-in AI analyst that empowers anyone on the team to explore data through SQL, Python, or intuitive visualizations. Briefer’s unified interface eliminates the friction of juggling multiple tools, making it easier to transform raw data into actionable insights efficiently and collaboratively.
Final thoughts
The stages of ingestion, storage, transformation, orchestration, and delivery form the backbone of a modern data engineering workflow. The challenge is not merely selecting the right tools but designing a system where each component fits cohesively with the others.
Over-engineering leads to brittle complexity; under-engineering leaves you firefighting. The goal is to strike a balance that supports current needs while providing enough flexibility to evolve with future demands.
Ultimately, designing an effective data engineering workflow is about more than technology. It’s about creating a reliable, maintainable system that enables your team to focus on delivering value rather than patching broken pipelines. Structure should serve as a scaffold for efficiency and innovation, not as a bureaucratic straitjacket.
Create clean analysis and dashboards 10x faster. Try Briefer for free!