
It takes a bit to fool a Neural Network. This is the surprising adversarial attack: a technique designed to deceive neural networks by making tiny changes to an input.
These attacks aren't just about causing trouble. By learning how to attack these systems, we find their hidden weak spots. This is one important step towards fixing them and building safer AI for everyone.
To understand how to fool a neural network, we first need to understand it works.
Know Your Enemy
Imagine we give a neural network a simple job: separating the toppings on a half-and-half pizza, with pineapple on one side and pepperoni on the other. The AI model learns to draw a line separating the toppings by looking at examples - thousands of other half'n'half pizza toppings placements. The line's exact position is defined by the model's internal parameters, a set of numbers that the model tunes during the training process.
The training process starts with a guess. The model draws a random line and checks how many toppings it classified incorrectly, which gives an error measure. We search for the line that reduces this error.
The first idea is to compute all possible lines and select the best one. Unfortunately, there are many of them - infinite ones. Thus, it's impossible to compute lines one by one. Starting with a random line does not means we are lost. Instead, we might use a guide that tells how to find a better one.
The guide comes from maths: the gradient is a tool that explain which network parameters should change to increase the error. Since we want to reduce the error, we change the parameters in the opposing way and find a line that decreases the error. We iteratively find better lines with decreasing error using the gradient. Line after line, we find the one which best separate the toppings.
This line, which separates pineapples from pepperonis, is called a decision boundary.
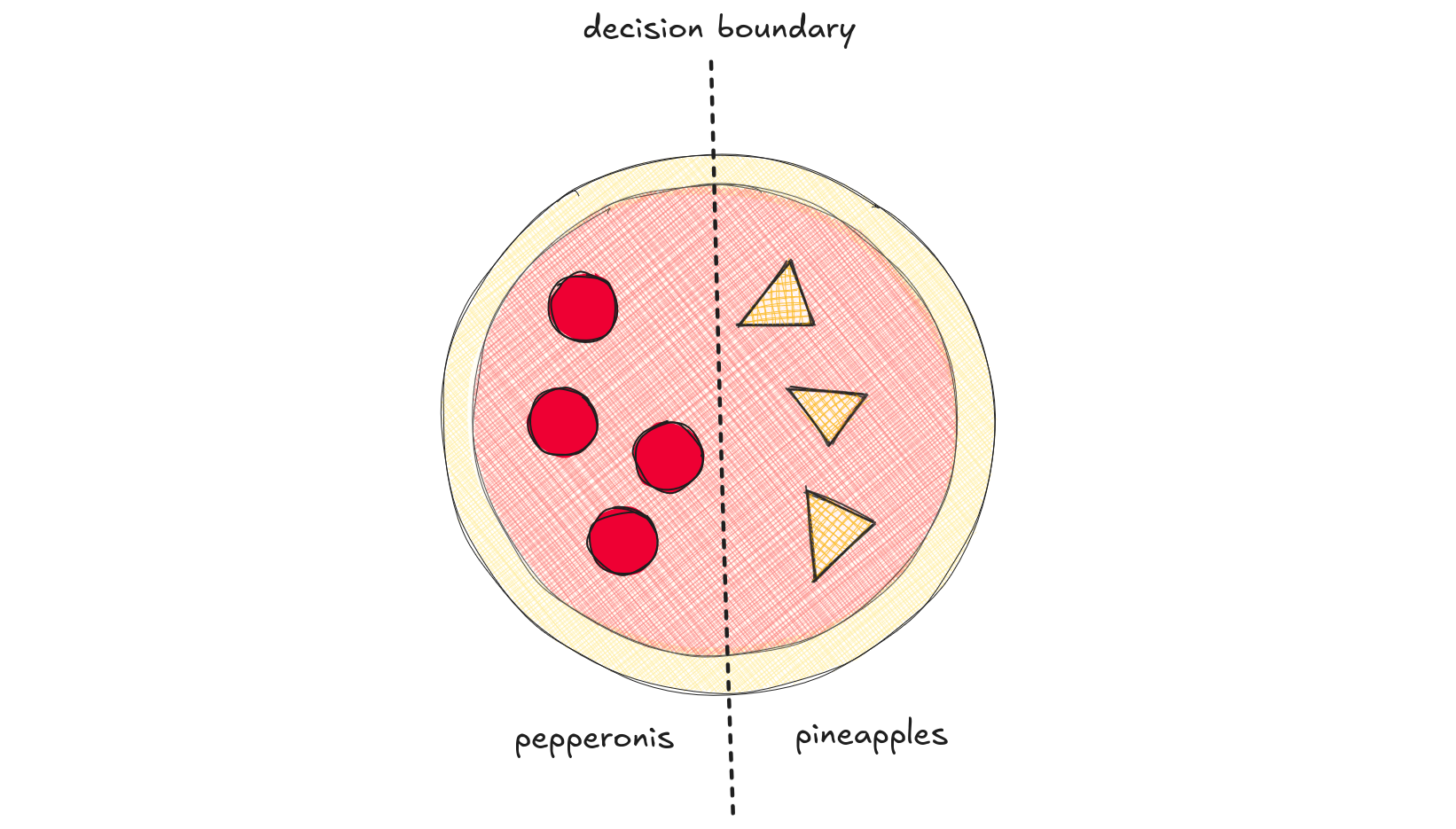
This is a simple scenario where the decision boundary is just a straight line: we call it a linear classifier. The network learned that the toppings side - right or left - are important thing to classify them.
Knowing our adversarial attack target, we can now deceive it.
How to Fool a Neural Network
To fool the simple pizza network, all we need to do is change the important thing about the toppings: for example, moving a single pepperoni across the decision boundary. The network, following the learned parameters, is deceived into classifying that pepperoni as a pineapple.
There are many ways to cross the decision boundary, but not all of them are good.
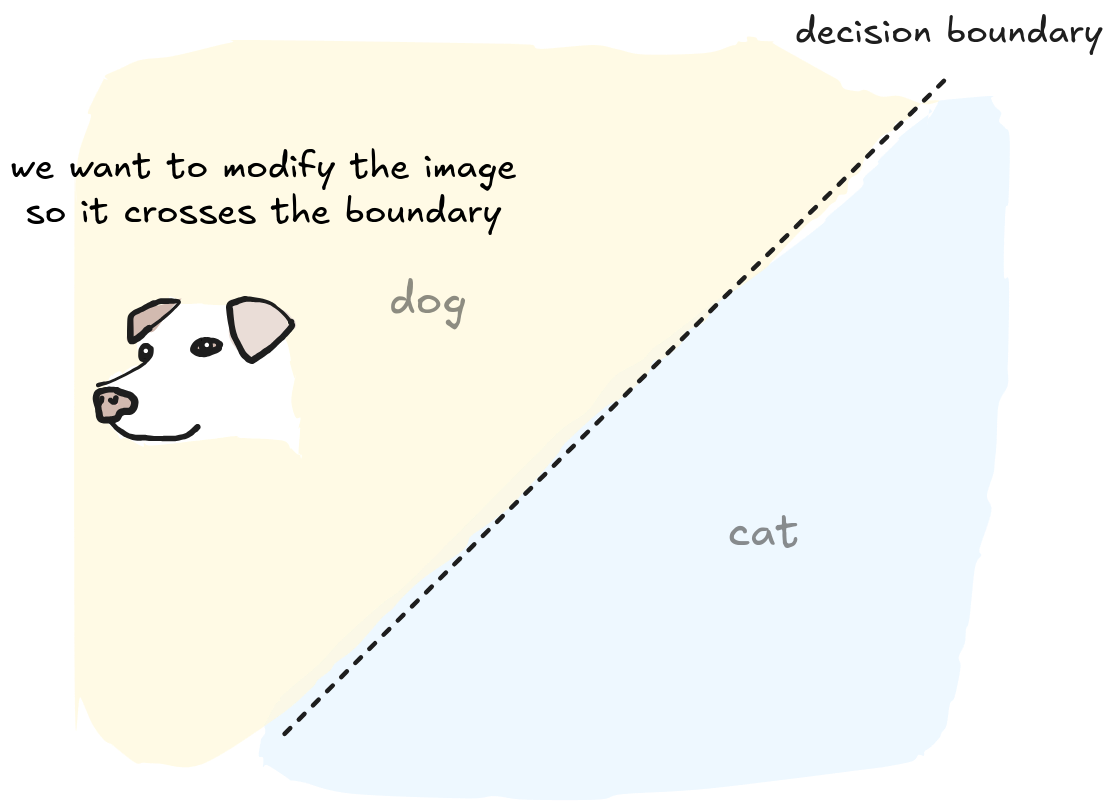
Consider a neural network trained to distinguish dogs and cats. The network classifies a dog image correctly. To fool it, we must make the network classify the dog image as a cat. If we add whiskers, pointy ears, and a pink nose to the dog, it will cross the boundary and be identified as a cat. But at the end, we modified the image so much it really became a cat!
![]()
We must make a modification that is powerful enough to move the image across the decision boundary, but subtle enough to be invisible. This means we will find the smallest change in the image that makes it cross the boundary. How can we find this perfect, tiny change on an image to fool a network?
The most efficient way to move the image through the decision boundary is to follow the shortest path. Imagine you're standing in a large, open field and want to reach a straight road. The quickest way is to walk in a straight line, perpendicular to the road. Any other path would be longer. In the same way, the most efficient path for our image to cross the decision boundary is a line perpendicular to it.
To find this perpendicular path, we can repurpose the gradient.
During training, the gradient told us changes to the model's parameters that increased the error. In that phase, we took the opposite direction to find parameters that minimized the error. Now, the gradient show us how to change the image's pixels and fool the model.
The gradient gives us the exact direction for this path. In geometric terms, finding the shortest distance from a point (our image) to a line (the decision boundary) is done via a projection. The gradient points along this projected line, and by moving our image in that direction, we move in the direction of the most efficient path to cross the boundary.

This works well with a linear decision boundary. But the real world is rarely that simple.
Dealing with real Neural Networks
To handle complex tasks like identifying a dog in a photo, we need a tool thousands of parameters more powerful than a linear boundary decision: Deep Neural Networks (DNNs).
Unlike our simple model, a DNN is made of many layers of classifiers stacked on top of each other. The first layer learn to spot simple things, like colors and edges. The next layer combine those edges to recognize simple shapes, like a curved ear or a wet nose. A deeper layer still might combine those shapes to identify a whole dog's face. This layered hierarchical structure allows DNNs to understand incredibly complex patterns.
To handle complex data, these layers work together to stretch and squeeze the data's space. Imagine a messy pile of pineapples and pepperonis on a pizza dough. By stretching the dough in just the right way, you could pull the pineapples and pepperonis apart so a single straight line could separate them. This is what a DNN learns to do.
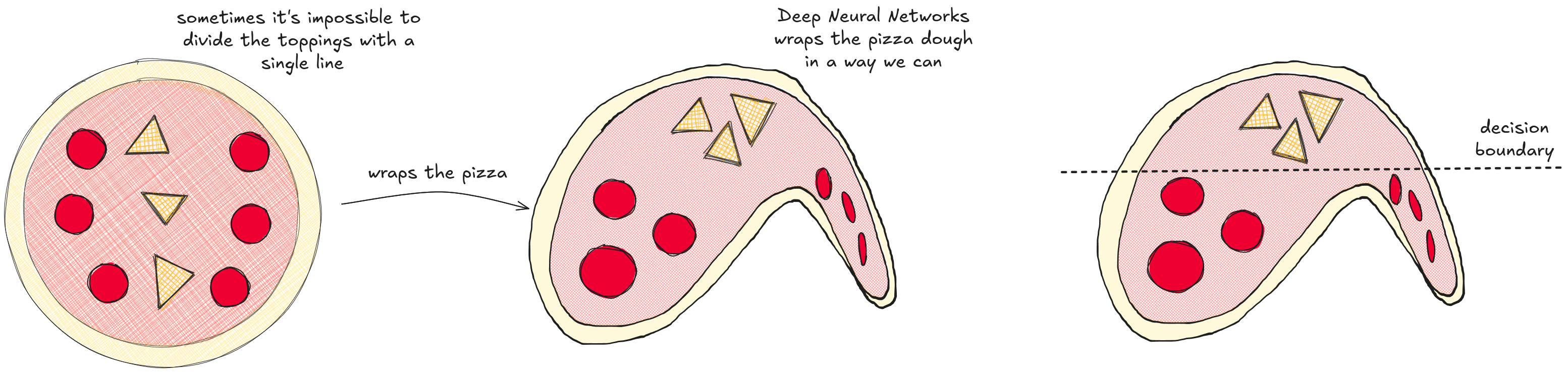
Each layer performs one of these stretches, and by the end, the data is so neatly organized that it can be easily classified. This process of distorting space represents a decision boundary that is no longer a simple line, but a vast, high-dimensional surface.
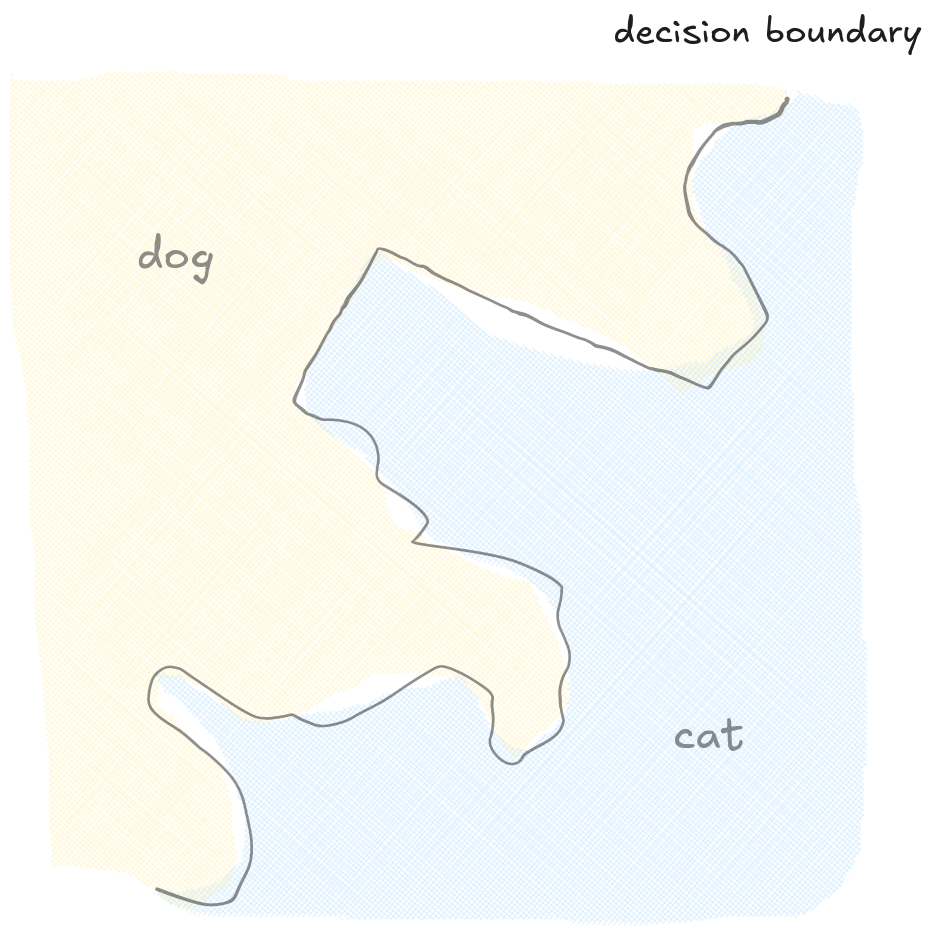
The goal of an attack is still the same: move the image across the decision boundary to fool the model. But because the boundary is so complex, the path to deceive the network is much harder to find.
We need a clever insight.
That complex, high-dimensional surface is incredibly difficult to navigate. But we can borrow a trick from physics: simplify the problem by looking at it on a very small scale. Physicists simplify problems all the time. For example, the swinging motion of a pendulum is described by a complex equation. But for very small swings, physicists use an approximate equation that is much easier to solve. Even if more simple, it is still highly accurate for small swings.
We can apply the same principle here to simplify the boundary. Just like the Earth is a sphere but appears flat if you're only looking at your immediate surroundings, even the most complex decision boundary looks like a simple flat surface if you zoom in close enough.
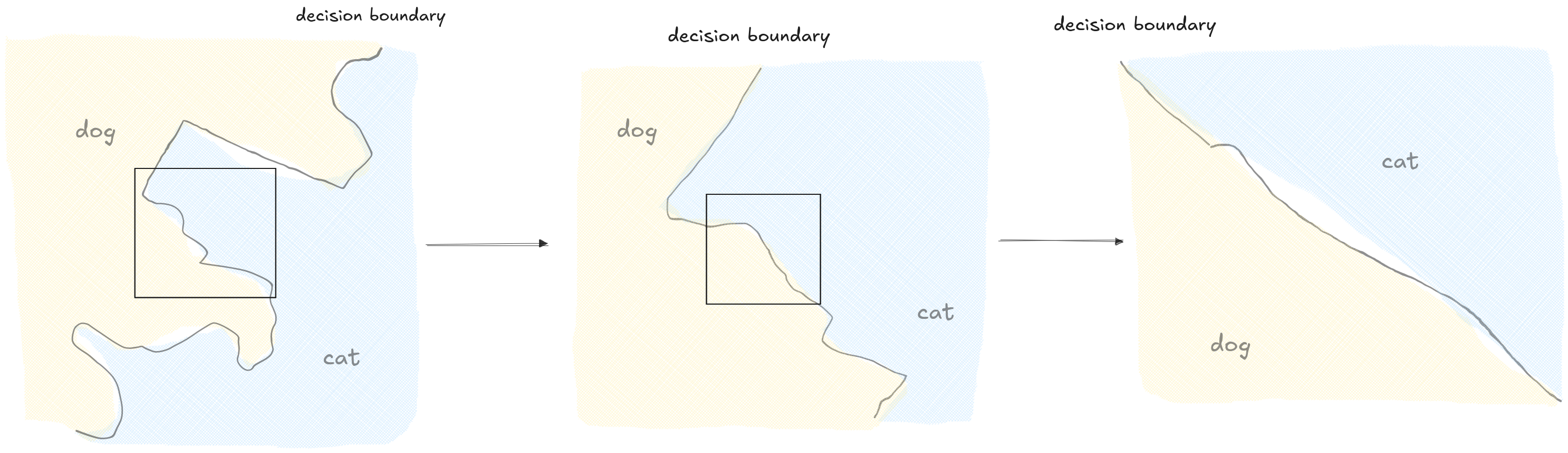
Since it's possible to approximate the complex boundary as a flat surface, we can still use the gradient to find the shortest path across this local section of the boundary.
However, this flat surface approximation is only accurate right where we are standing. If we take a big step in this direction, we might miss the boundary, and our path will no longer be the shortest one.
From this new position, we can recalculate the gradient and take another small step. Step by step, we navigate the complex surface, always following the most efficient path, until crossing the decision boundary, successfully deceiving the network.
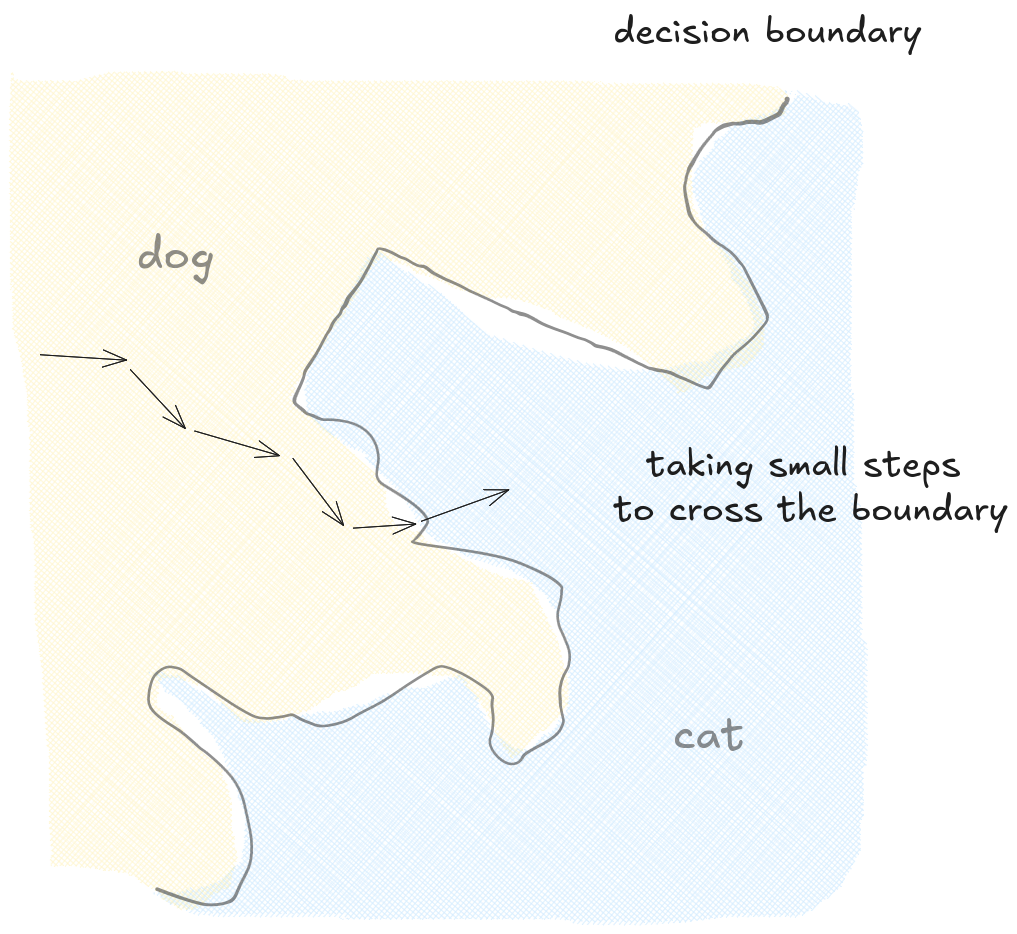
The step-by-step method we just described is powerful, but it requires seeing inside the network to access its internal parameters and calculate the gradient. In the real world, however, we usually can't see the model's internal logic. We are effectively working blindfolded.
The only information we get back is a set of confidence scores. For example, the network might return 90% confidence for "dog" and 10% for "cat," telling us how sure it is about its decision.
These confidence scores are directly linked to the decision boundary. An image that is far from the boundary - like a very clear picture of a dog - will receive a high confidence score. But an image that is very close to the boundary, one that could almost be a cat, will receive a lower confidence score. The closer an image gets to crossing the boundary, the more the model's confidence drops.
This gives us a new clue. We may not have the gradient, but we can use these confidence scores as a compass. We search for tiny changes on the image to cross the boundary. To make the challenge even more realistic, consider one final limitation. We are only allowed to make the smallest possible change: modifying a single pixel.
It takes a bit to fool a Neural Network
Is it possible to fool a deep neural network using only confidence scores and a one-pixel modification?
Analyzing a change one by one gives us no clue of what's happening.
We could try a simple "guess and check" approach. We have the confidence scores, so we could just start changing pixels randomly, one by one, and see what happens to the score. But an image has millions of pixels. The odds of randomly picking the right pixel and changing it in the right way are way to low. This would be like trying to find a single grain of sand on a huge beach by picking up one at a time.
Without the gradient, we have no idea on how to change the image or what direction to follow. Instead of analyzing a single image at a time, we can analyze two images, each with a different and randomly changed pixel. When fed to the network, they produce two new confidence scores. For instance, the first change might drop the "dog" confidence to 70%, while the second increases it to 95%.
The first modification was clearly more effective at confusing the network. It represents a better direction.
This gives us our first clue. We discard the less effective change and keep the one that worked better. Then, using this slightly modified image as our new starting point, we create two new random modifications from it and test them. Again, we pick the better of the two and repeat the process. Each step takes us a little closer to the decision boundary. After many such steps, we might find the single pixel change that drops the network's confidence all the way down to 10%.
From here, we follow an iterative process. In each step, the less effective change is discarded, and a new pair of modifications is created, centered around the "better" one just found. This is just like taking small steps in the correct direction. By repeating this process, the image slowly but surely walk towards the decision boundary.
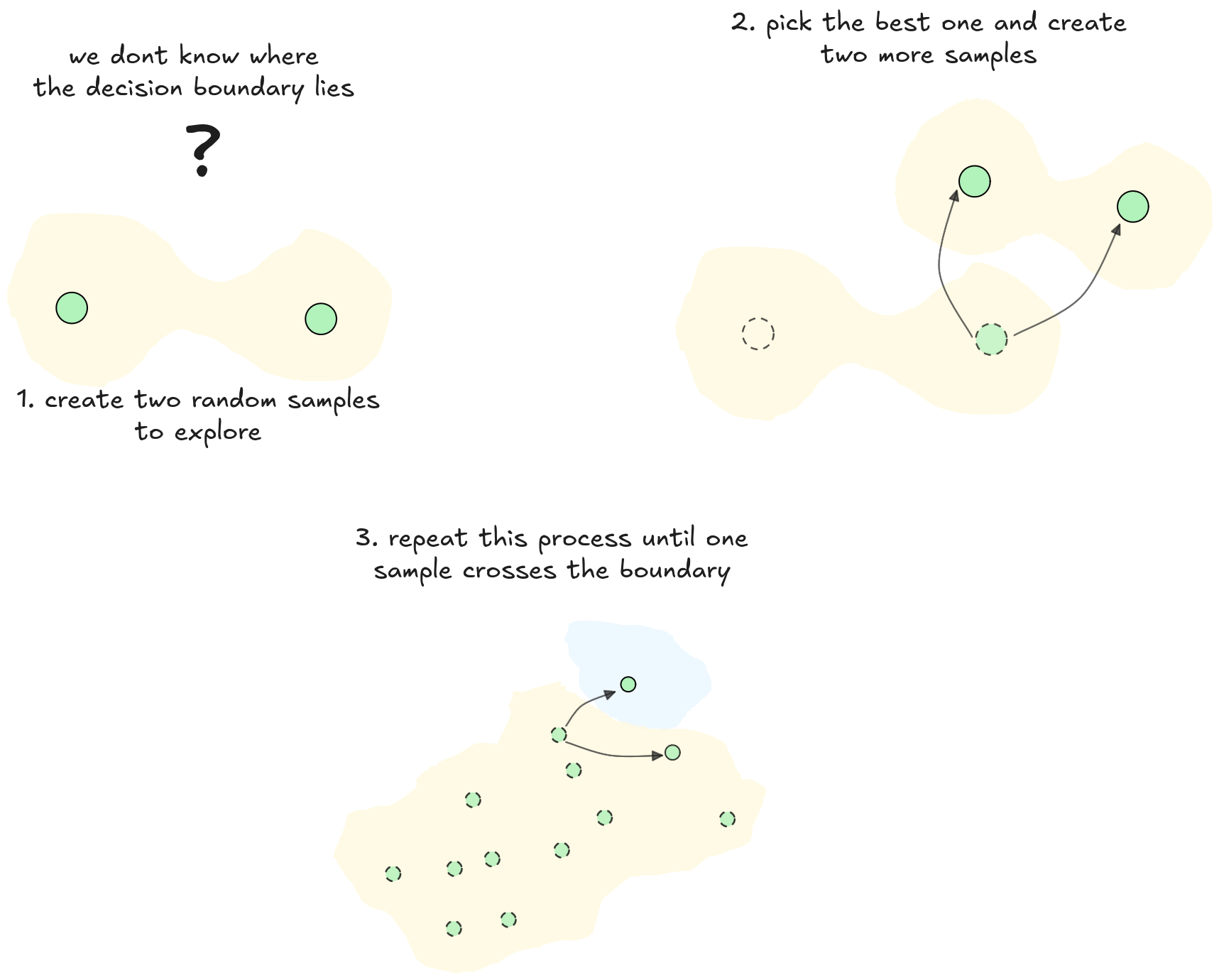
This step-by-step improvement is a good start, but we can make it much more powerful. Instead of testing just two modifications at a time, we can test hundreds in parallel. We create a whole "population" of slightly different images and see which ones are best at confusing the network. We then take the most successful images and use them to create a new generation of variations.
This process, which mimics natural selection, is the core idea behind evolutionary algorithms. By testing many variations at once, evolutionary algorithms explore the possibilities effectively, eventually evolving into the perfect single-pixel change that fools the network.
This is the groundbreaking algorithm used to fool Neural Networks by modifying one pixel. At the end, even the most robust AI systems can have critical hidden (almost invisible!) vulnerabilities.
What's next?
We have successfully fooled a deep neural network with a single pixel. So, what's next?
Even if it looks fun, adversarial attacks are a critical part of building safer AI. Understanding how to attack a system is the first step toward defending it.
One of the most common defense methods is called adversarial training. It's like vaccinating the model. During its training, we intentionally show it these tricky adversarial images and teach it the correct label (e.g., "this is still a dog"). This helps the model learn about attacks, making the decision boundary more robust and harder for an attacker to cross.
The field is a constant cat-and-mouse game, with new attacks and defenses pushing AI to become more reliable and secure. This cycle is essential for developing better models which are robust, transparent and secure. Protect your models!