
At Briefer, we are building multiplayer notebooks. That means many users can edit and run blocks in the same notebook at the same time.
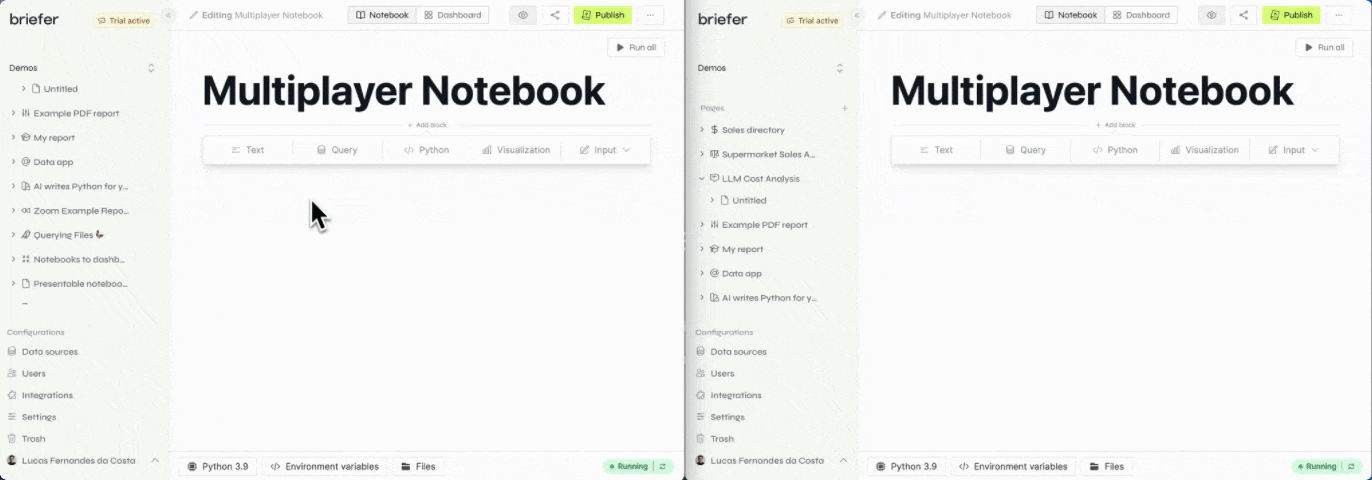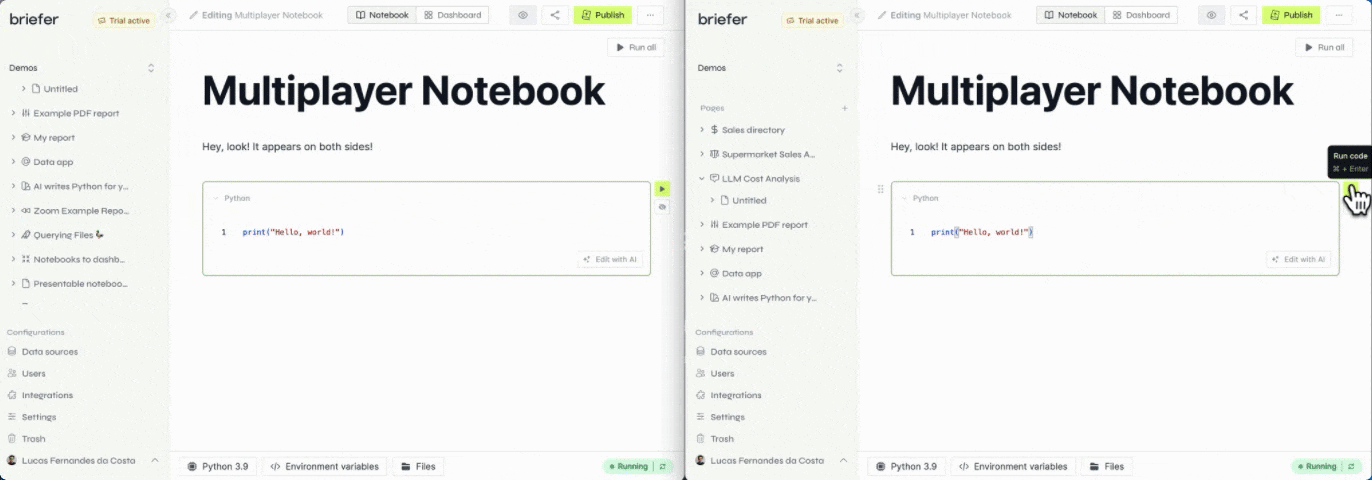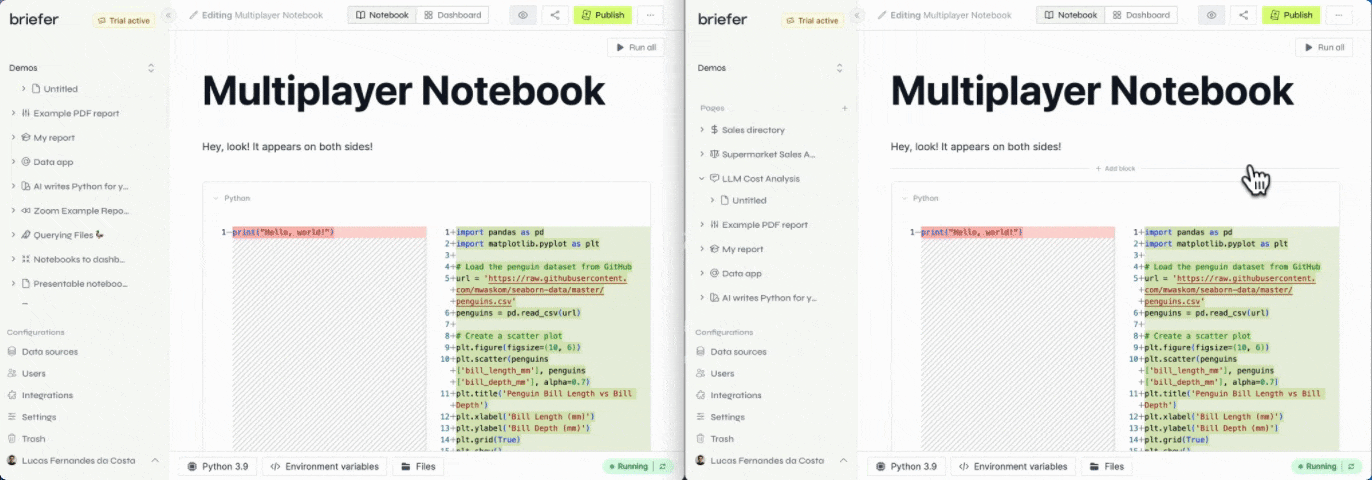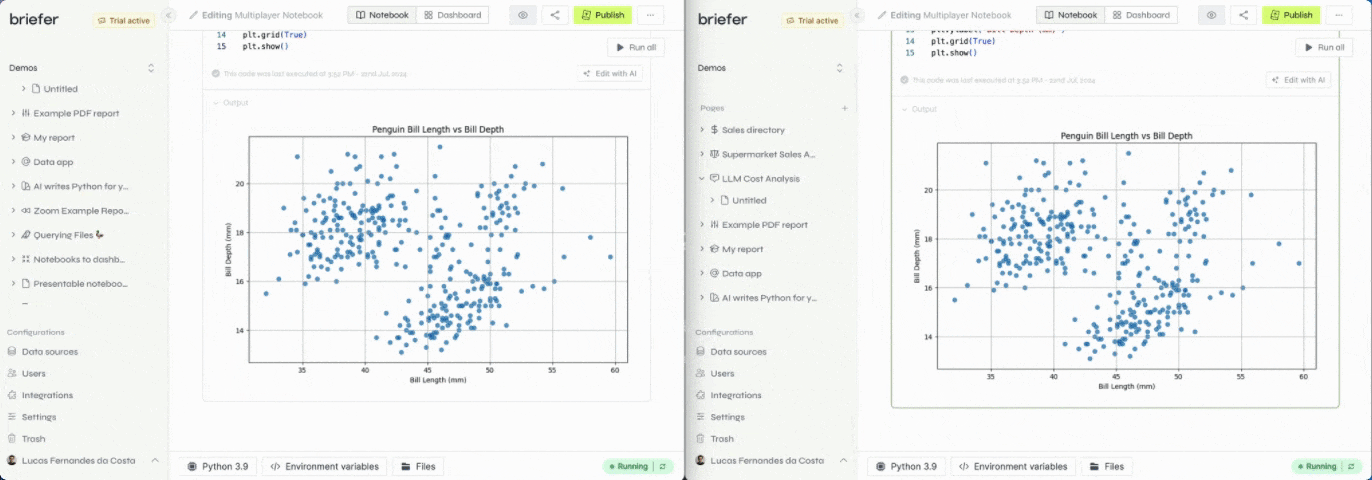
In this post, I'll explain how we got to multiplayer notebooks that actually work.
First, I'll describe Jupyter Notebook's architecture, and how we built a single-player v0 on top of it.
Then, I'll explain what CRDTs are, how they handle conflicts and collaborative editing, and how we used them to build a multiplayer v1 that work reasonably well.
Next, I'll walk you through the problems we had with v1, and show how we solved them in v2 by communicating changes directly through CRDTs.
Finally, I'll share a few lingering issues we have with v2 and what we're planning to do next.
v0: Building a notebook
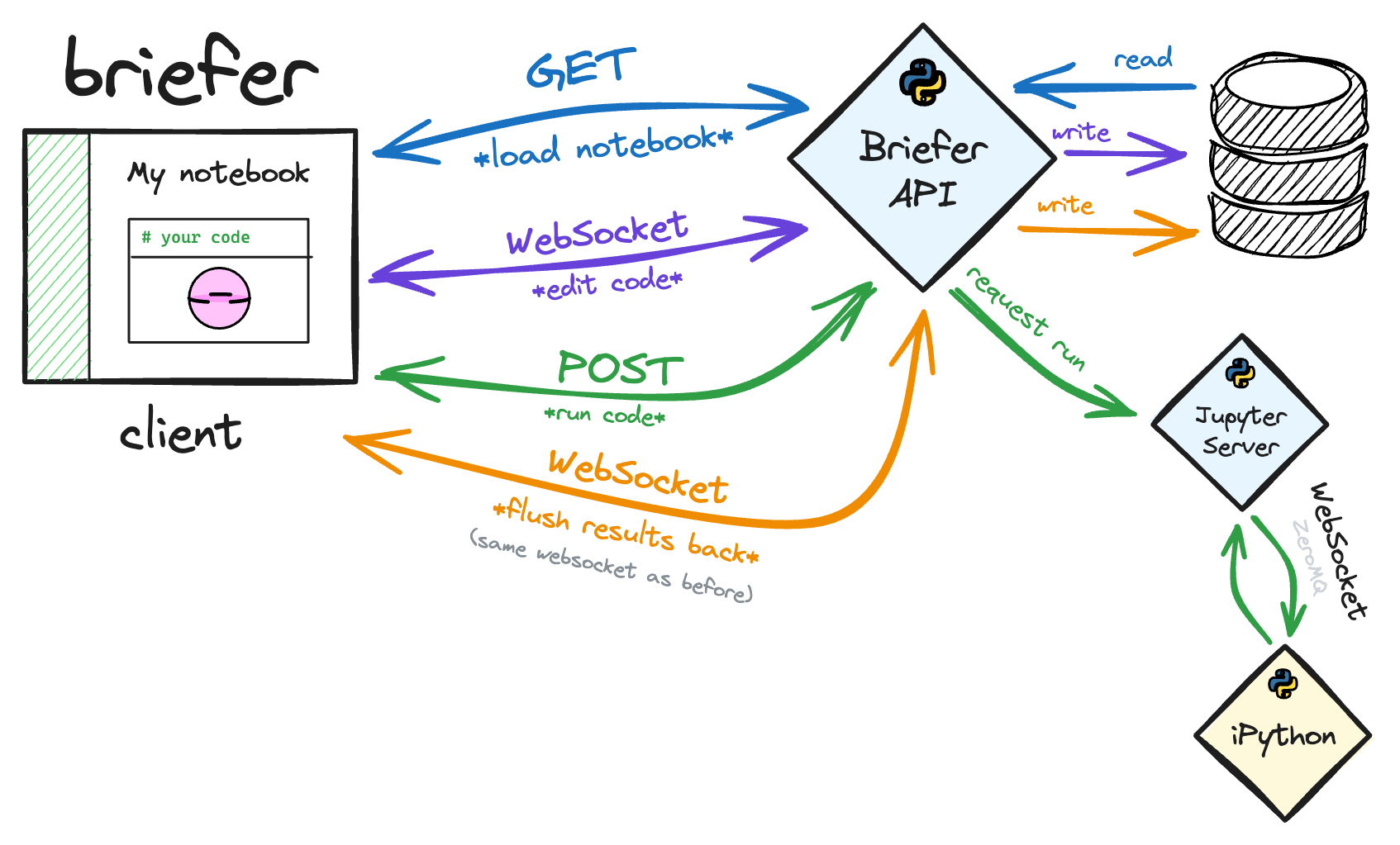
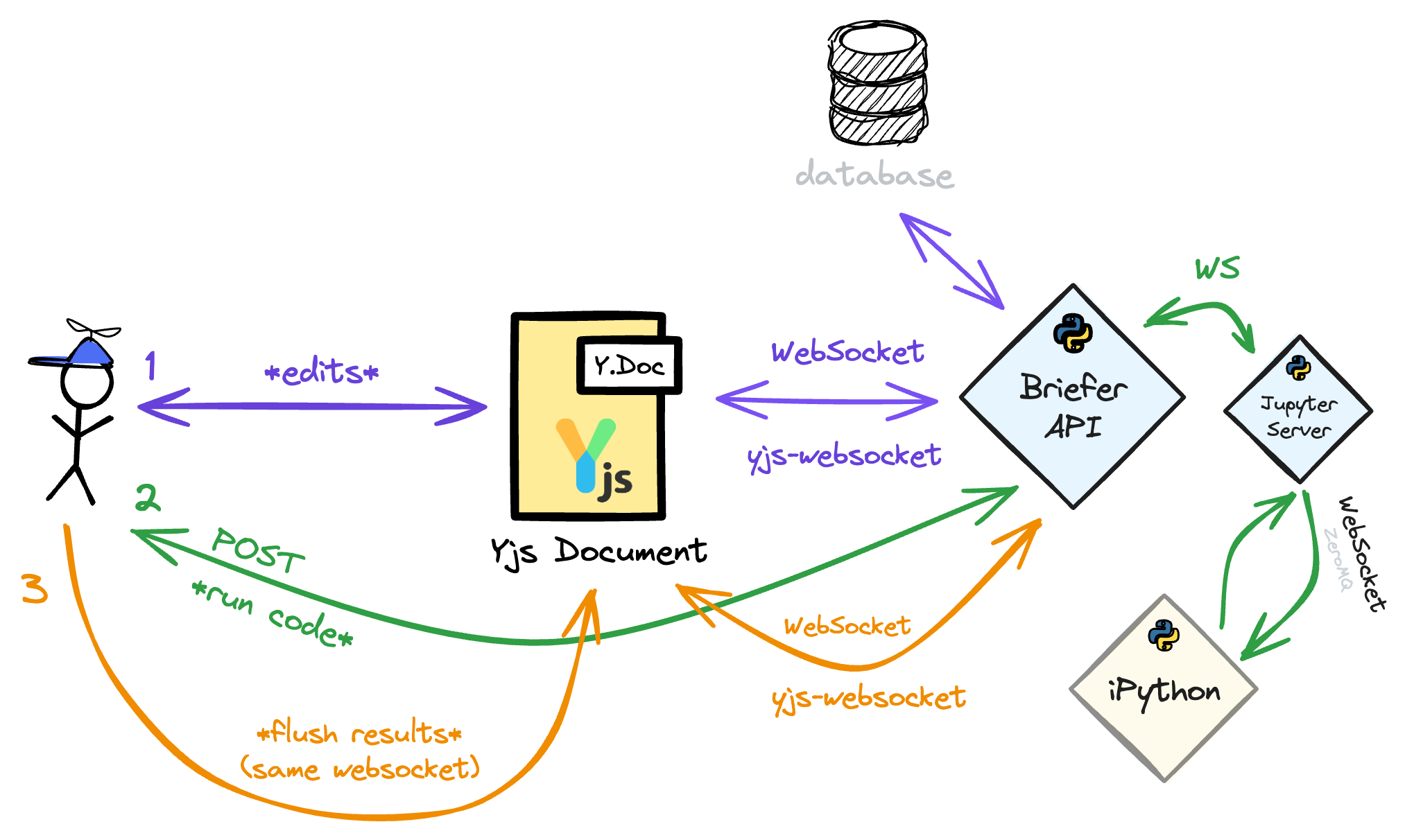
Most people think Jupyter Notebooks are monolithic, but they're actually a collection of three major components that work together: the Jupyter Notebook client, the Jupyter Server, and the IPython kernel.
When most people talk about Jupyter Notebooks, they're referring to the Jupyter Notebook client. That client is a JavaScript application that talks to a Python application called the Jupyter Server over a WebSocket.
Whenever you run a block of code in a Jupyter Notebook, your browser writes to the WebSocket from which the Jupyter Server is reading. The Jupyter Server then responds by writing the output back to the WebSocket, which the client reads and renders.
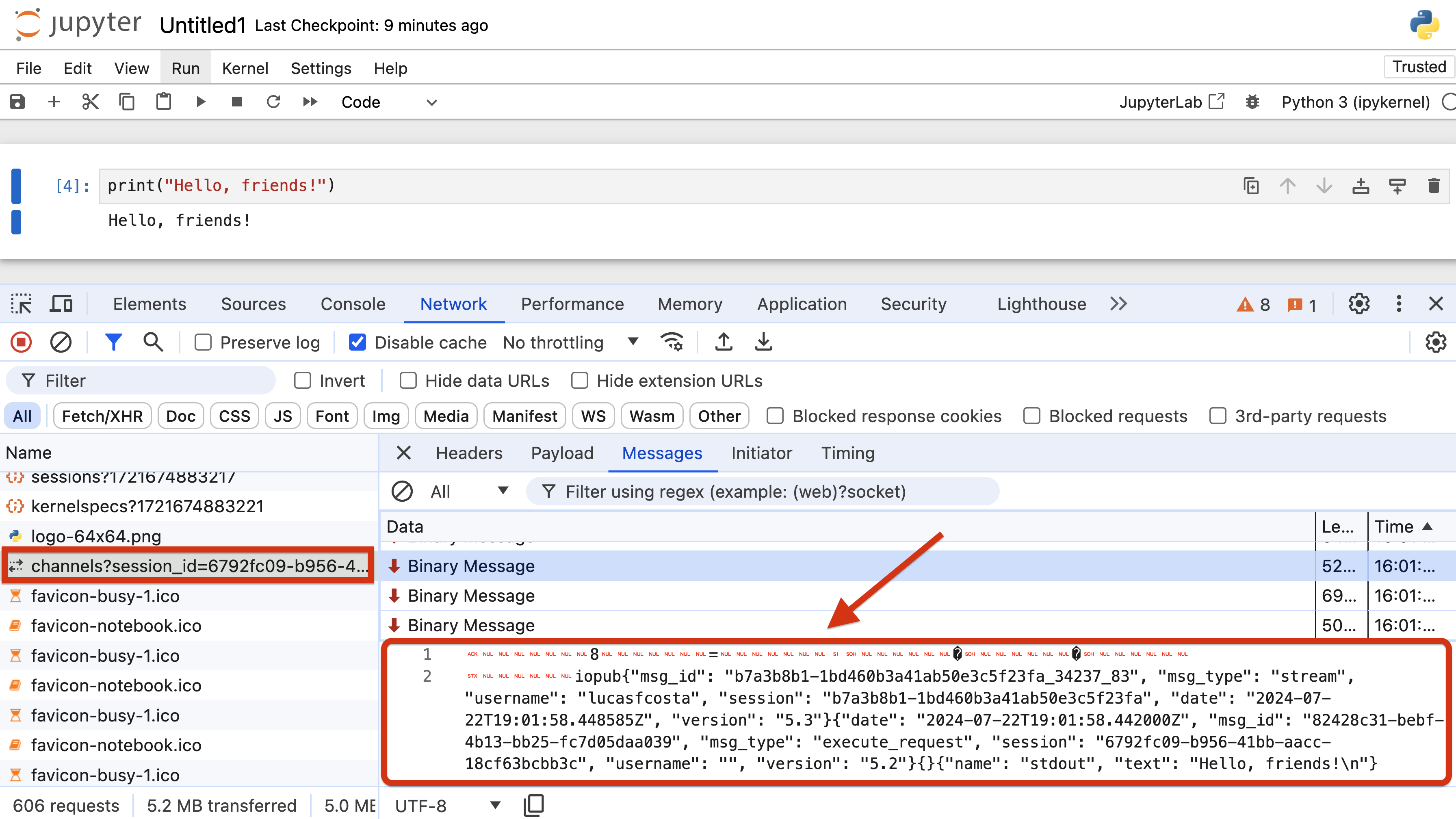
Still, the Jupyter Server does not run the code itself. Instead, it sends the code to an IPython kernel through a ZeroMQ socket using the Jupyter messaging protocol.
It's that IPython kernel process that actually runs the code. Then, it sends the output back to the Jupyter Server, which, in turn, sends it back to the Jupyter Notebook client. If necessary, the server can also write to and read from the notebook's .ipynb file.
This decoupled architecture makes it easier to build new types of notebooks without reinventing the wheel. Instead of reimplementing everything from scratch, people can just build clients that talk to the Jupyter Server and render outputs.
For example, if you like pain and text-based interfaces as much as I do, you could use the Qt console and earn some extra street cred (or lose some, depending on who you ask).
In the same way, you could build a better notebook client that works in the cloud. You could, for example, wrap SQL code in a Python function and offer native SQL support in your notebooks. That's what we did at Briefer.
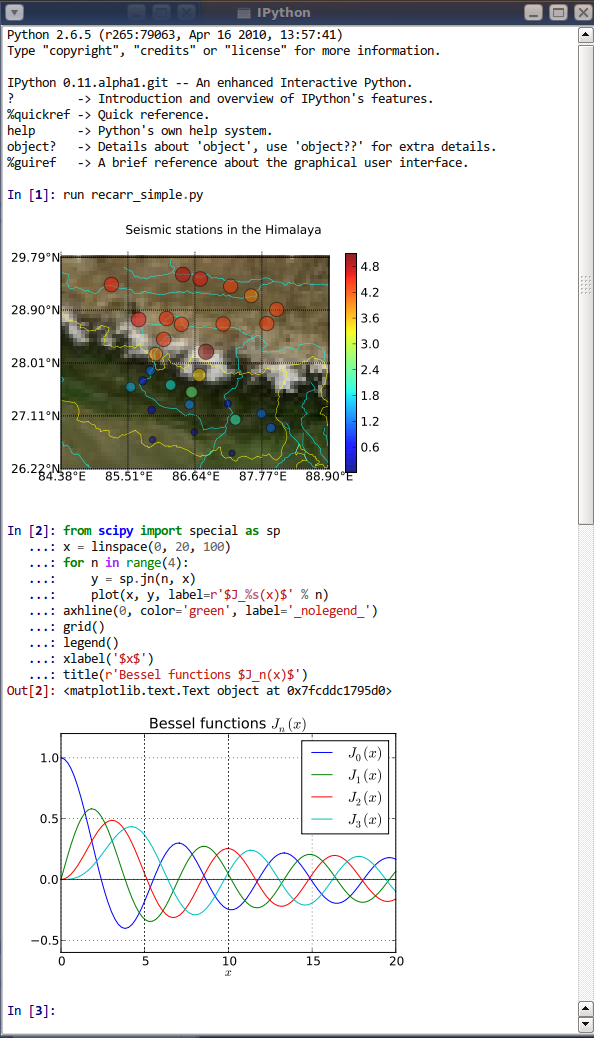
Our v0 was a single-page app that talked to our API which then relayed commands to the Jupyter Notebook server for that user's workspace. For each notebook in a workspace, the Jupyter Notebook server would maintain a separate IPython session.
In addition to that application, we also had a database where the notebooks' contents were stored.
Whenever users opened a notebook, the Briefer client sent a GET request to the backend and render the results. As users edited the notebooks, we'd write the changes to a websocket to keep the backend in sync.
Finally, whenever someone wanted to run a block of code, they'd send a POST request to the backend, which would run the code and return the output. Once the client received the output, it would write it to the notebook and flush the result back to the server.
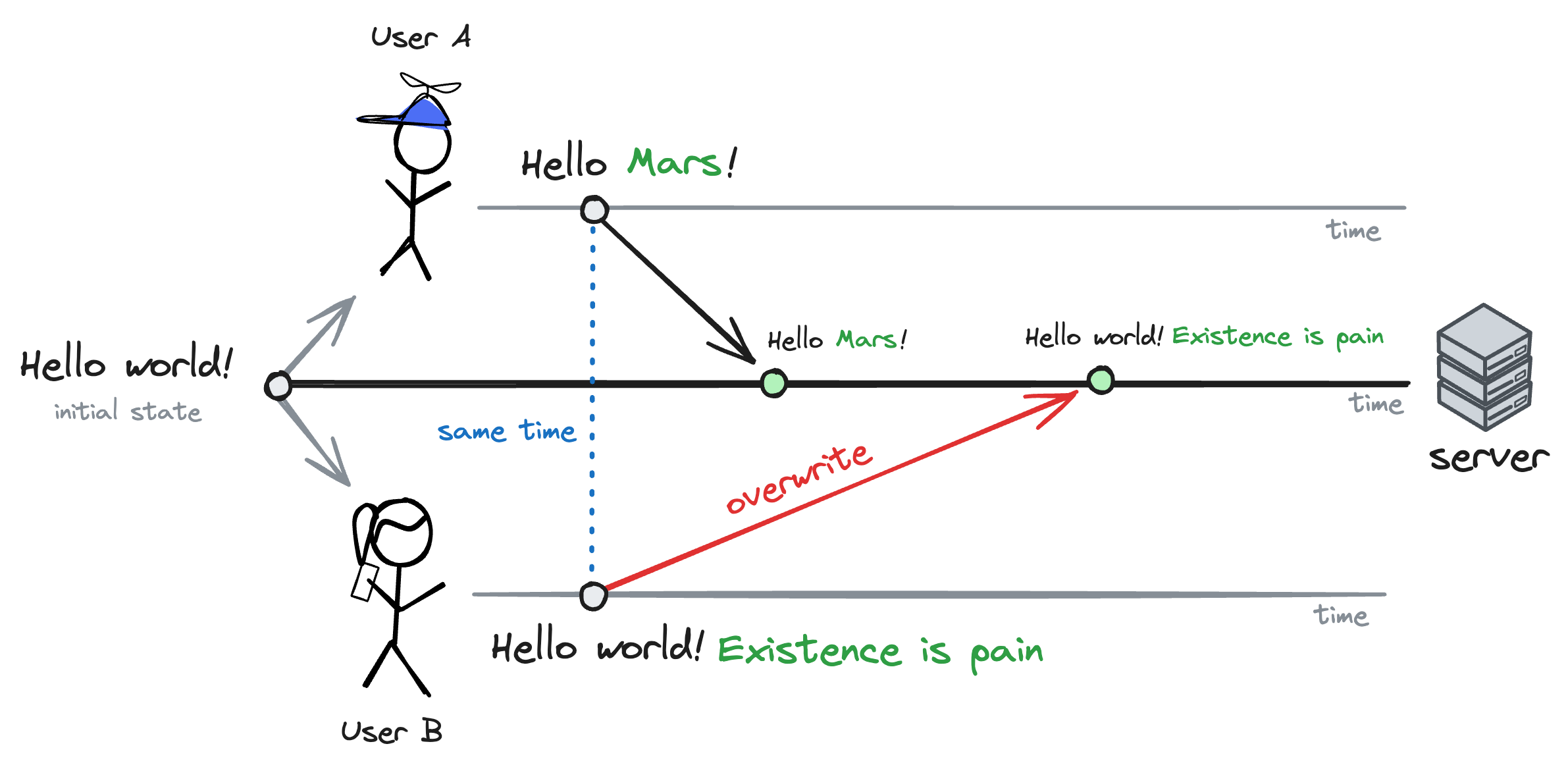
This architecture worked great, except for one thing: only one person could edit the notebook at a time. Whenever two people tried to edit the same notebook, the last person to save their changes would overwrite the other person's changes.
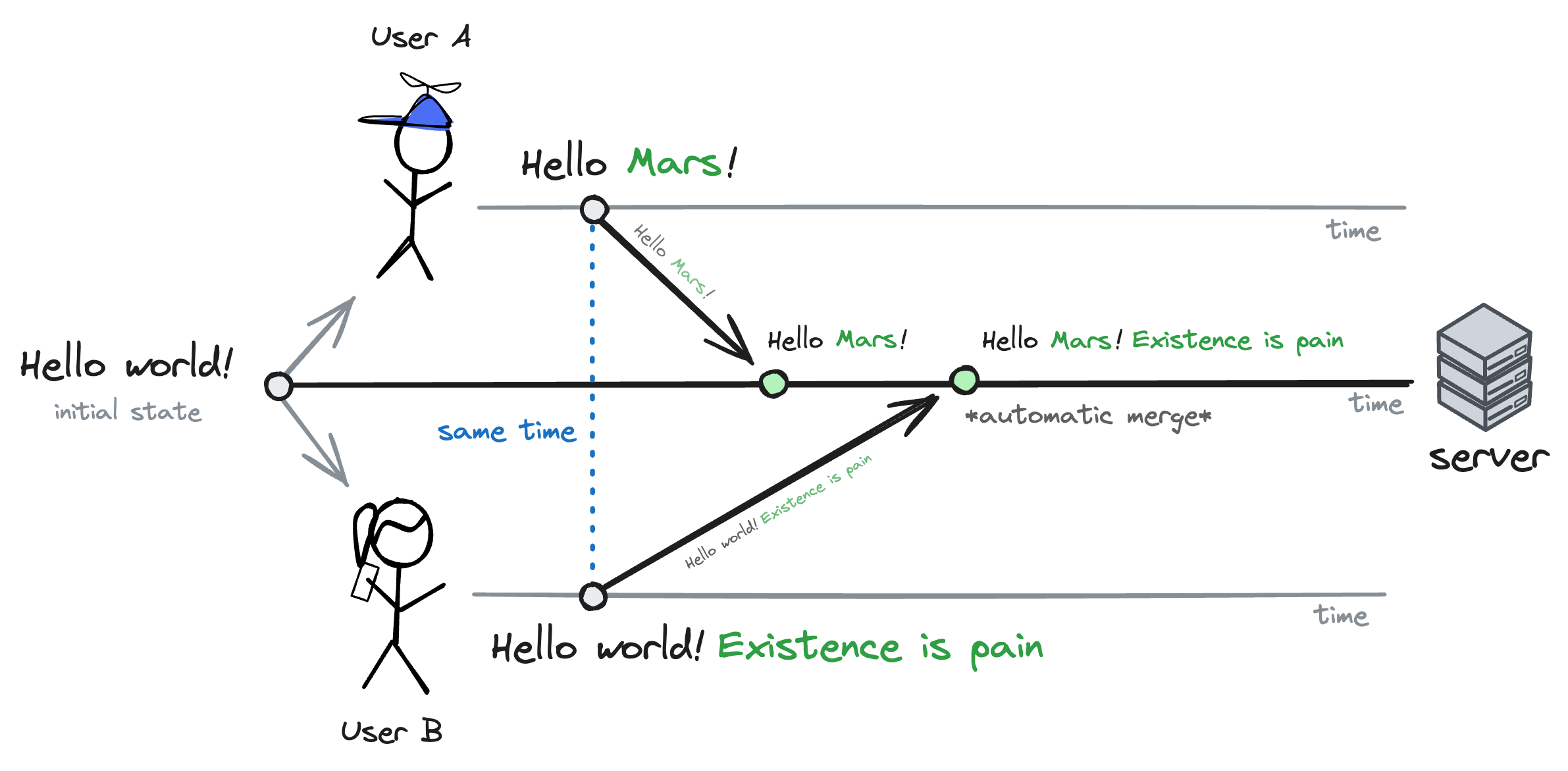
Let's say users A (latency = 50ms) and B (latency = 250ms) wanted to edit a print("Hello world!") block, for example. In that case, if user A changed it to print("Hello Mars!") and user B simultaneously changed it to print("Hello world! Existence is pain"), the end-result would be print("Hello world! Existence is pain") because the server would receive user B's changes last.
At the time, we solved that problem by locking the notebook whenever someone started editing it. That way, only one person could edit the notebook at a time.
It was a dirty solution, but it helped us ship v0 in only a few days.
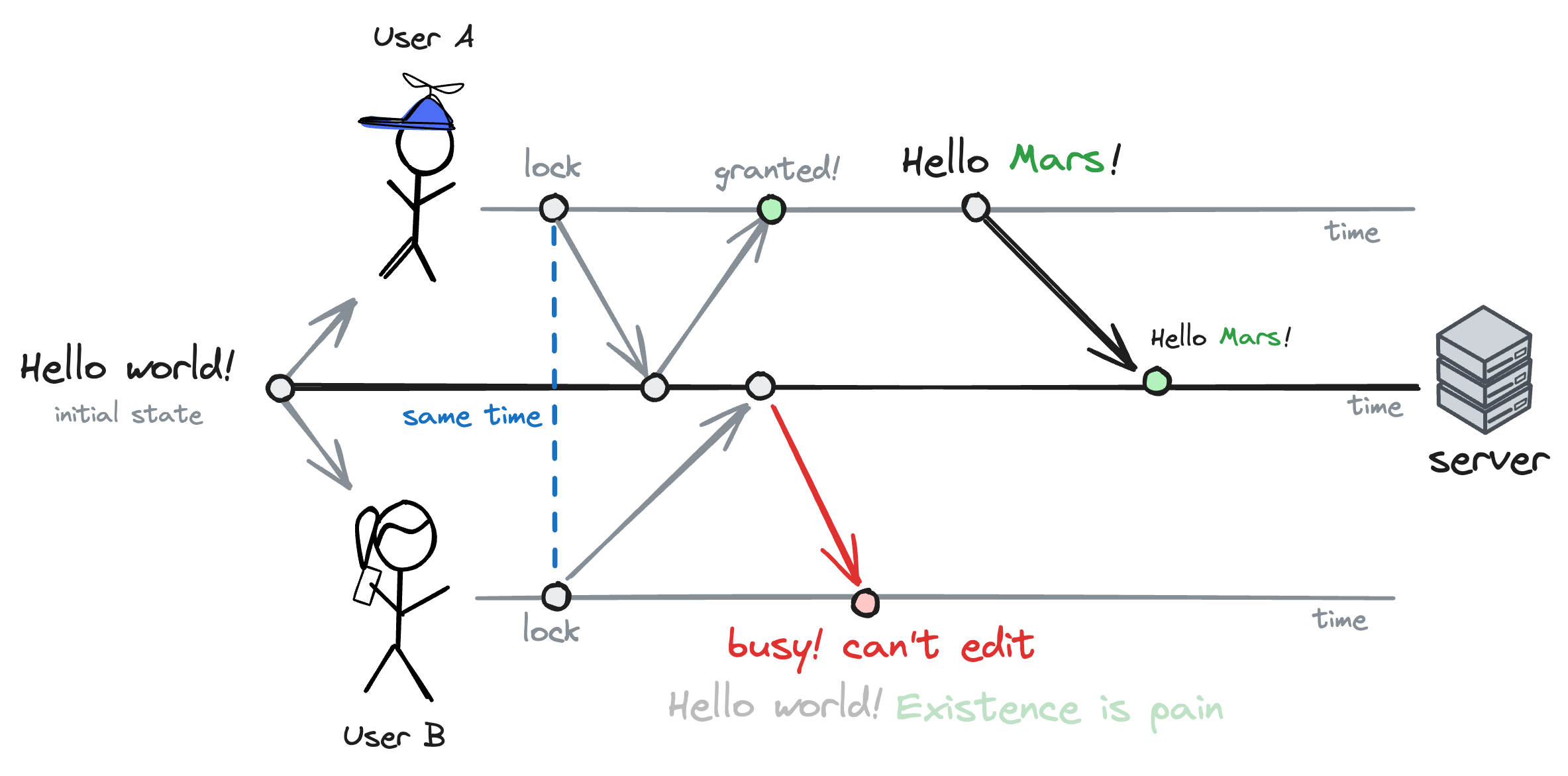
In a way, this is similar to how a typical mutex works in a multi-threaded application. Whenever a thread wants to access a shared resource, it locks the mutex. If another thread tries to access the same resource, it has to wait until the first thread releases the mutex.
Even though it was a suboptimal solution, it worked well enough for our first few users. These users just needed a cloud environment to write and run code in, and other quality of life features, like native SQL support, automatically turning query results into Pandas DataFrames, and a prettier interface to make their work more presentable to non-technical stakeholders.
That suboptimal solution also bought us time to work on a proper v1 with multiplayer support as users tested v0 and gave us feedback on a bunch of other things.
v1: Multiplayer notebooks that worked reasonably well
Let's start by exploring a conceptual solution to the multiplayer problem. Then, we'll dive into how we implemented it in v1.
A conceptual solution to the multiplayer problem
If we wanted notebooks to be truly multiplayer, we'd have to throw away our mutex-like approach and allow multiple people to edit the same piece of state at the same time.
The problem with simultaneous edits is that conflicts may happen. If two people edit the same piece of state at the same time, someone or something (preferrably) has to decide what the final state should be.
One way of solving this issue would be to break our notebooks' state into blocks. Then, instead of saving the entire notebook every time someone made a change, we saved the block that was edited only.
That way, multiple people could edit different blocks at the same time without conflicts. Additionally, we could sync each block's changes in real-time to everyone editing the notebook.
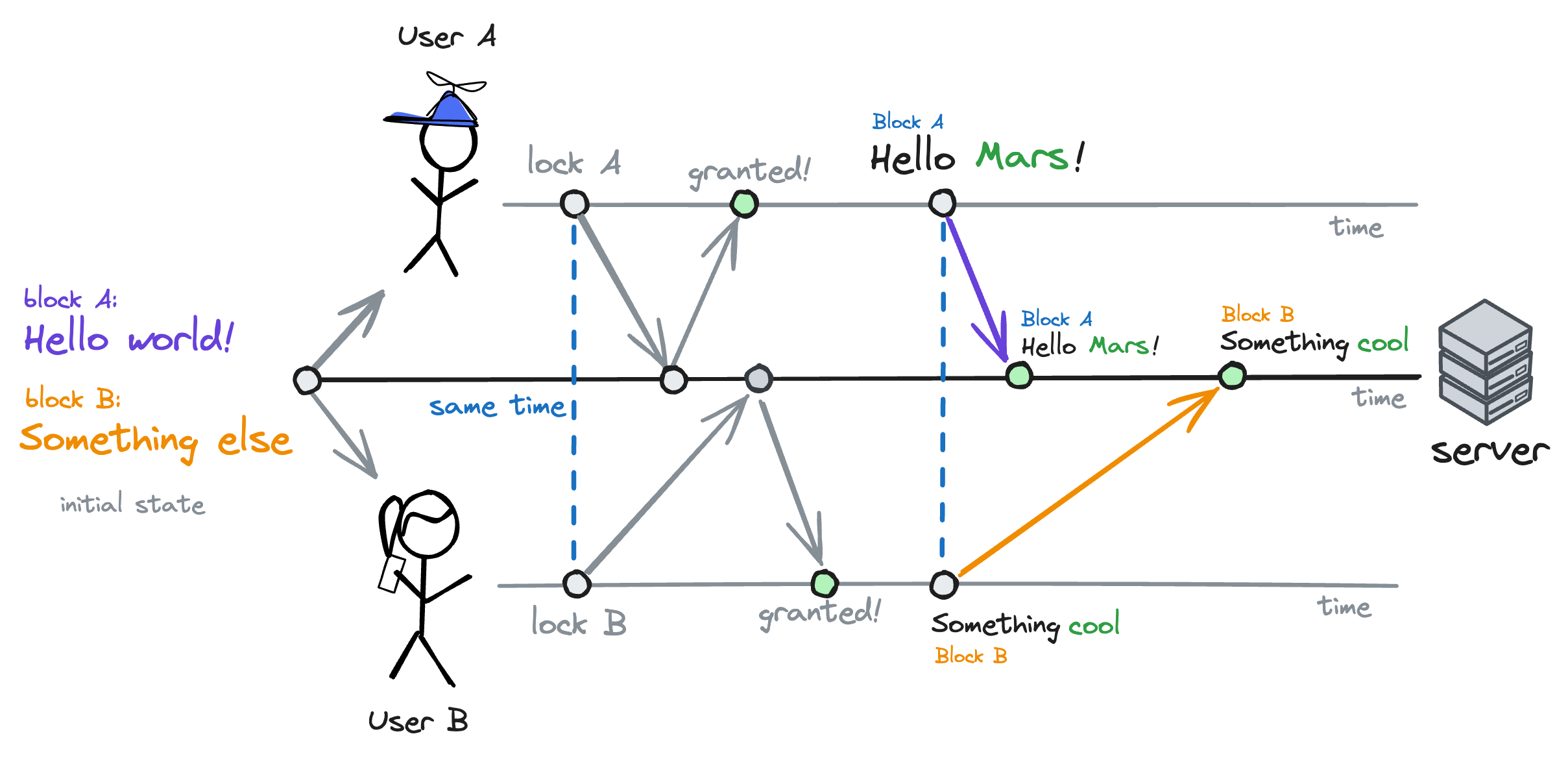
The problem with that approach was that it still wasn't possible to edit the same block at the same time. If I edited the notebook's first block and you edited the second, we wouldn't have any conflicts. However, a third person wouldn't be able to edit either block until we were done.
In a way, breaking the notebook's state into individual blocks simply meant that we moved our "mutex" from the notebook to the block level.
This is where CRDTs come in.
CRDT stands for Conflict-free Replicated Data Type. It's a type of data structure that is capable of automatically merging changes made by multiple users to the same piece of state.
Take that print("Hello world!") example from before. If user A changes it to print("Hello Mars!") and user B changes it to print("Hello world! Existence is pain"), the CRDT merges the changes automatically into print("Hello Mars! Existence is pain").
It does so because it knows that replacing world with Mars happened right after Hello and before !, while adding Existence is pain happened after !. That way, it can apply both changes in order and merge them automatically.
This approach is similar to what Git does when people edit different parts of the same file. If you change the first line of code and I change the last, Git will merge the changes automatically because its algorithm is programmed to do so.
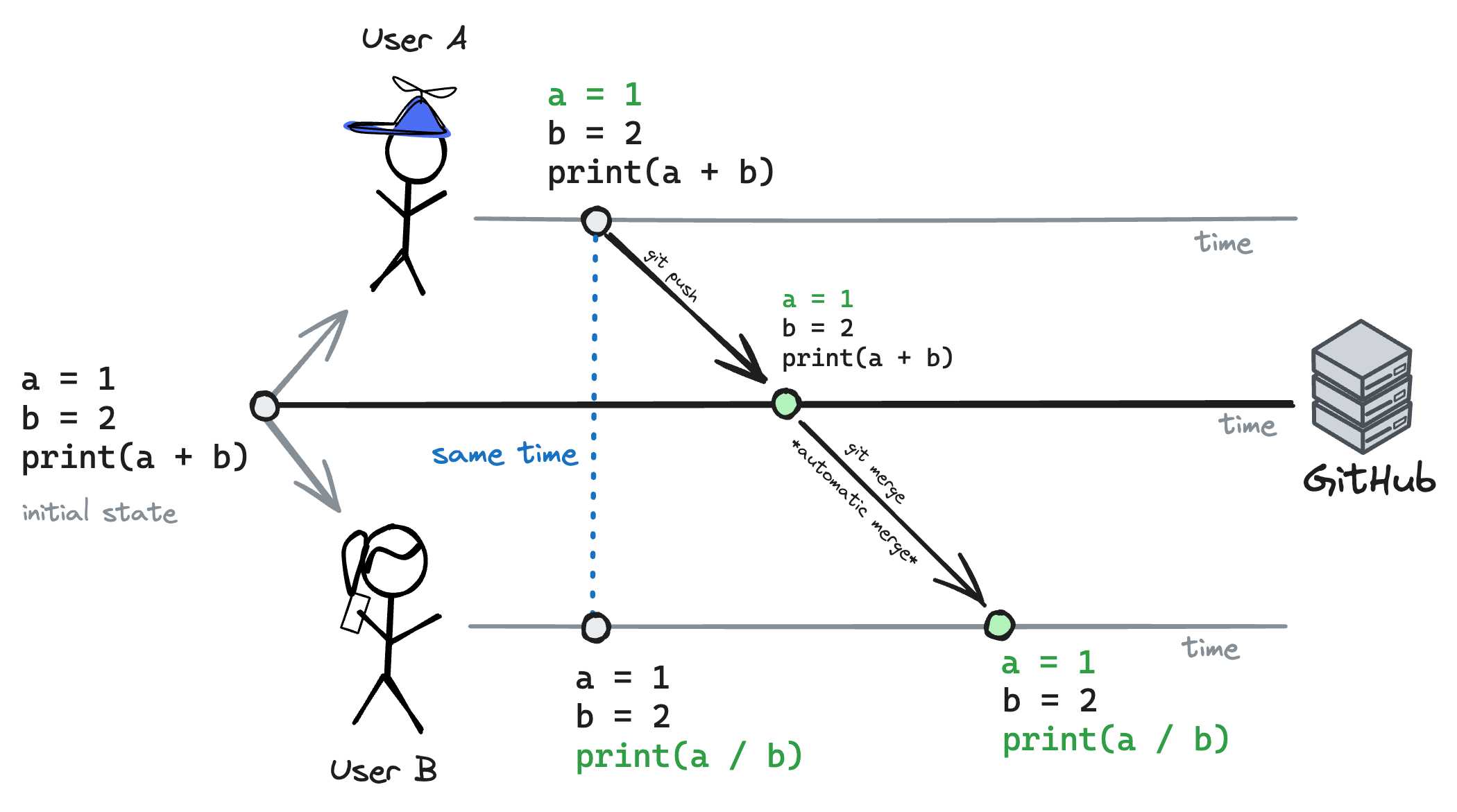
The difference between CRDTs and Git is that CRDTs can merge changes automatically even if they happen in the same line or in the same position within a line.
This way, if we turned each block's state into a CRDT, multiple people could edit the same block and the CRDT would merge the changes automatically, regardless of where they happened.
Finally, one last thing to notice about CRDTs as they do not care whether a merge's results are correct. They simply merge the changes automatically and ensure that the final state is consistent across all users.
Consequently, it's possible for two users editing the same block to end up with a block that doesn't make sense. For example, if user A changes print("Hello world!") to print("Hello Mars!") and user B simultaneously changes it to print("Hello Venus!"), the CRDT would merge the changes into print("Hello MarsVenus!").
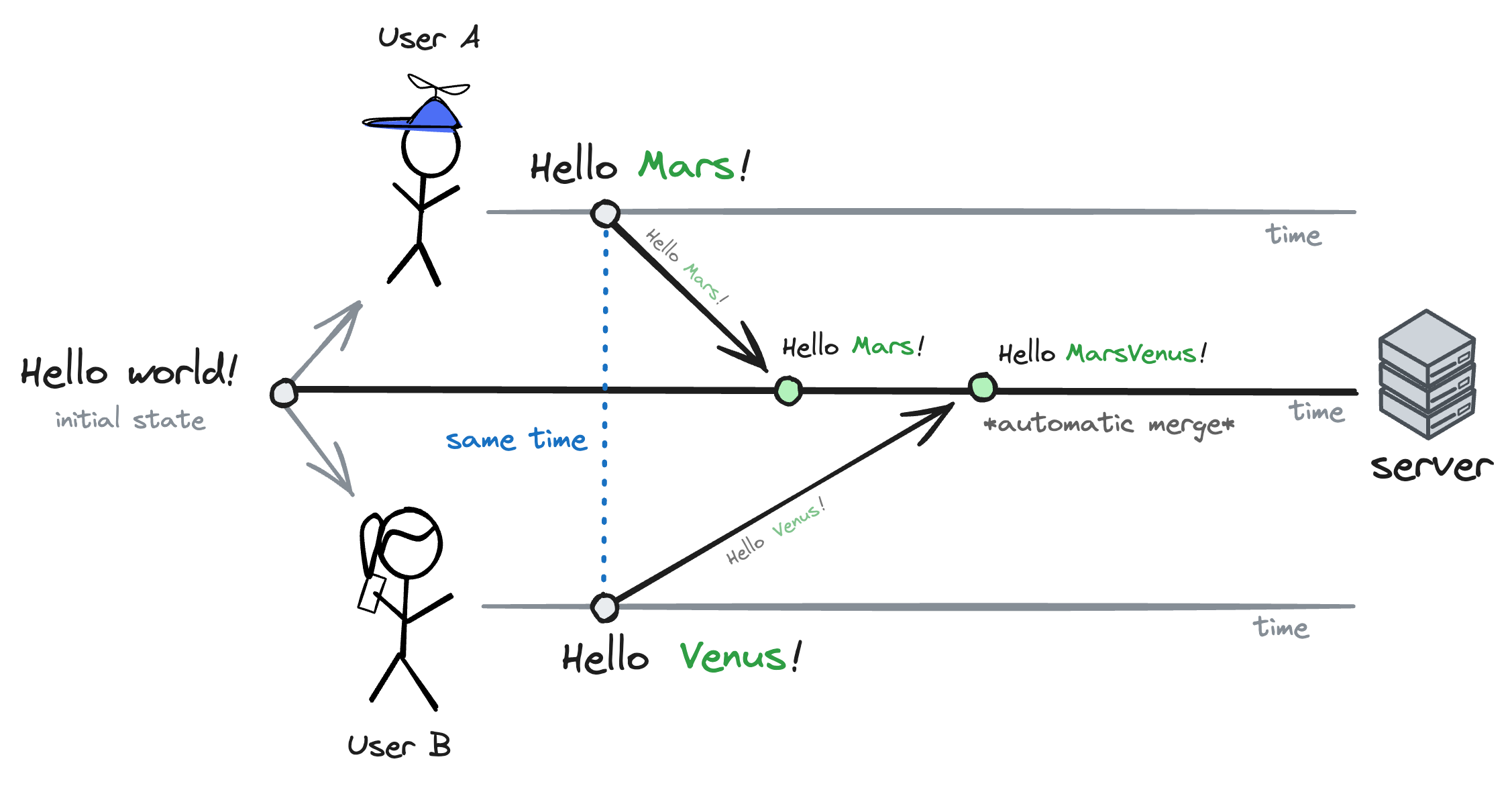
Still, that conflict-resolution mechanism is okay for our notebooks because people see each other's changes in real-time. That way, they can avoid getting in the way of each other.
Furthermore, it's unlikely for two people to edit the same position within block at the same time. In comparison, Git can't tolerate these types of merges because people change files in isolation and only see other people's changes when they git pull.
That's all to say that CRDTs are not a good fit for every type of application, but they're a great fit for real-time collaborative applications like our notebooks.
v1 architecture
Now that we have a conceptual solution to the multiplayer problem, I'll dive into how we implemented it in v1.
At Briefer, we're huge nerds, but not that much. We didn't want to roll our own CRDT implementations. Instead, we had to find an implementation that worked-well and that was easy to integrate with the editor libraries we using in our text and code blocks, TipTap and Monaco.
Ideally, whichever library we chose would also be straightforward to integrate with our backend because we didn't want to write our own custom protocol either.
Considering these criteria, the obvious choice was to go with Yjs.
Yjs is a CRDT library written in JavaScript that implements a variety of data structures, like arrays, maps, and text. Each of these data structures is capable of handling conflicts automatically, as I described above.
Additionally, both TipTap and Monaco have built-in support for Yjs, and the Yjs team also maintains y-websocket, a WebSocket provider that makes it easy to sync Yjs data between multiple clients and a server.
We then wired up Yjs to our frontend and backend.
First, we moved over all notebook's state to a Y.Doc object containing two-top level keys: a layout array and a blocks map. The layout array references the blocks in the order they appear in the notebook, while the blocks map contains the blocks' content indexed by their IDs.
In each block, we also include at least one Y.XmlFragment that we pass to TipTap or Monaco. It's that Y.XmlFragment that these libraries write to and read from.
// This is a simplified example type Block = Y.XmlElement<{ id: string; title: string; type: "sql" | "python" | "text"; content: Y.XmlFragment; result: Y.XmlFragment; }>; type BrieferNotebook = Y.Doc<{ blocks: Y.Map<Block>; // In reality, layout is an array of arrays // because a single layout row can have multiple // tabs (one for each block) layout: Y.Array<string>; };
Finally, we used y-websocket to sync the Y.Doc object between the clients and the server. That way, whenever someone made a change to the notebook, Yjs would automatically merge the changes and sync them to everyone editing the notebook.
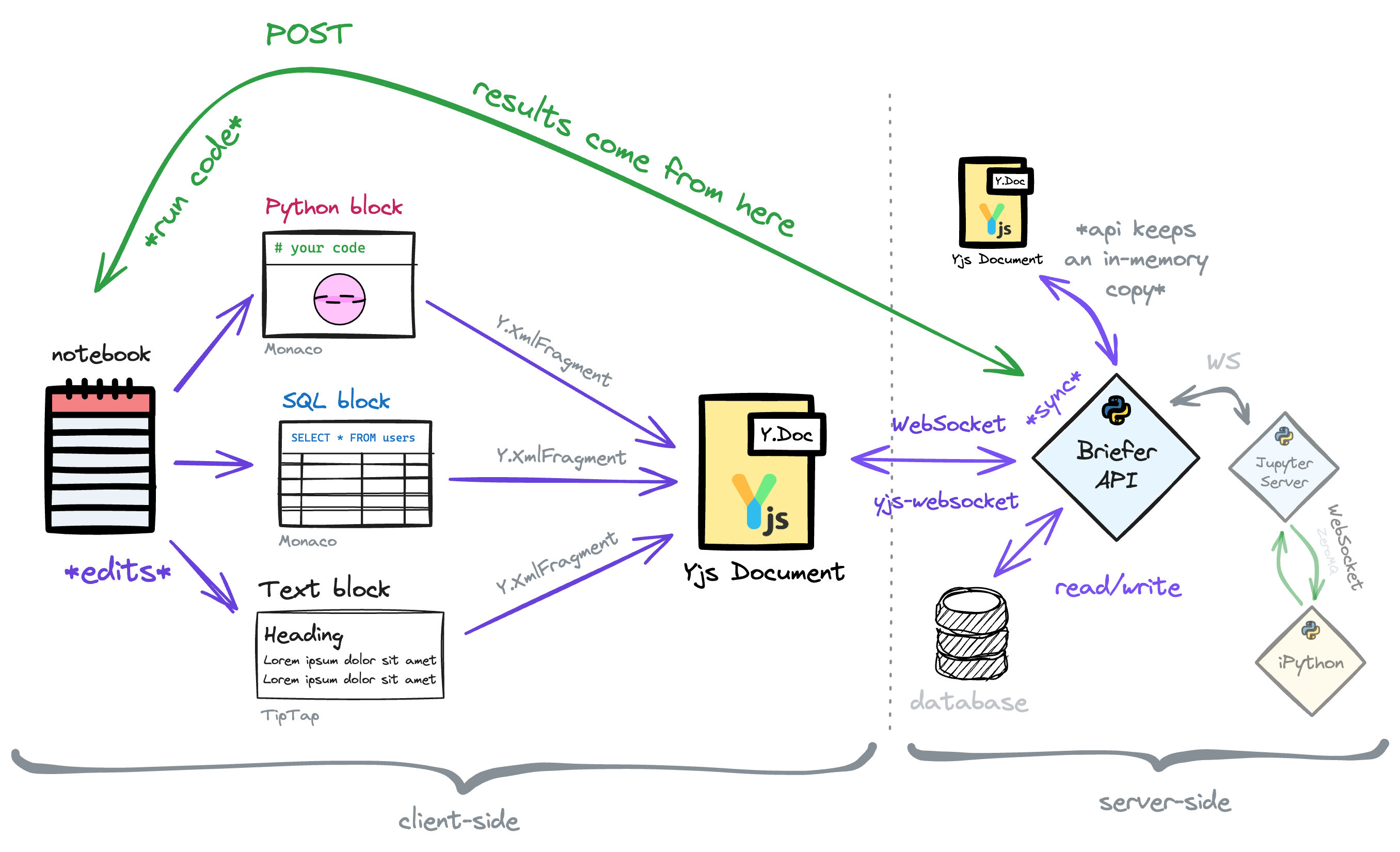
This architecture worked reasonably well, except for one thing: the way we handled block executions.
Whenever you ran a block of code in v1, the client would send a POST request to the backend, which would run the code and return the output. Once the client received the output, it would write it to the Y.Doc object and flush the result back to the server.
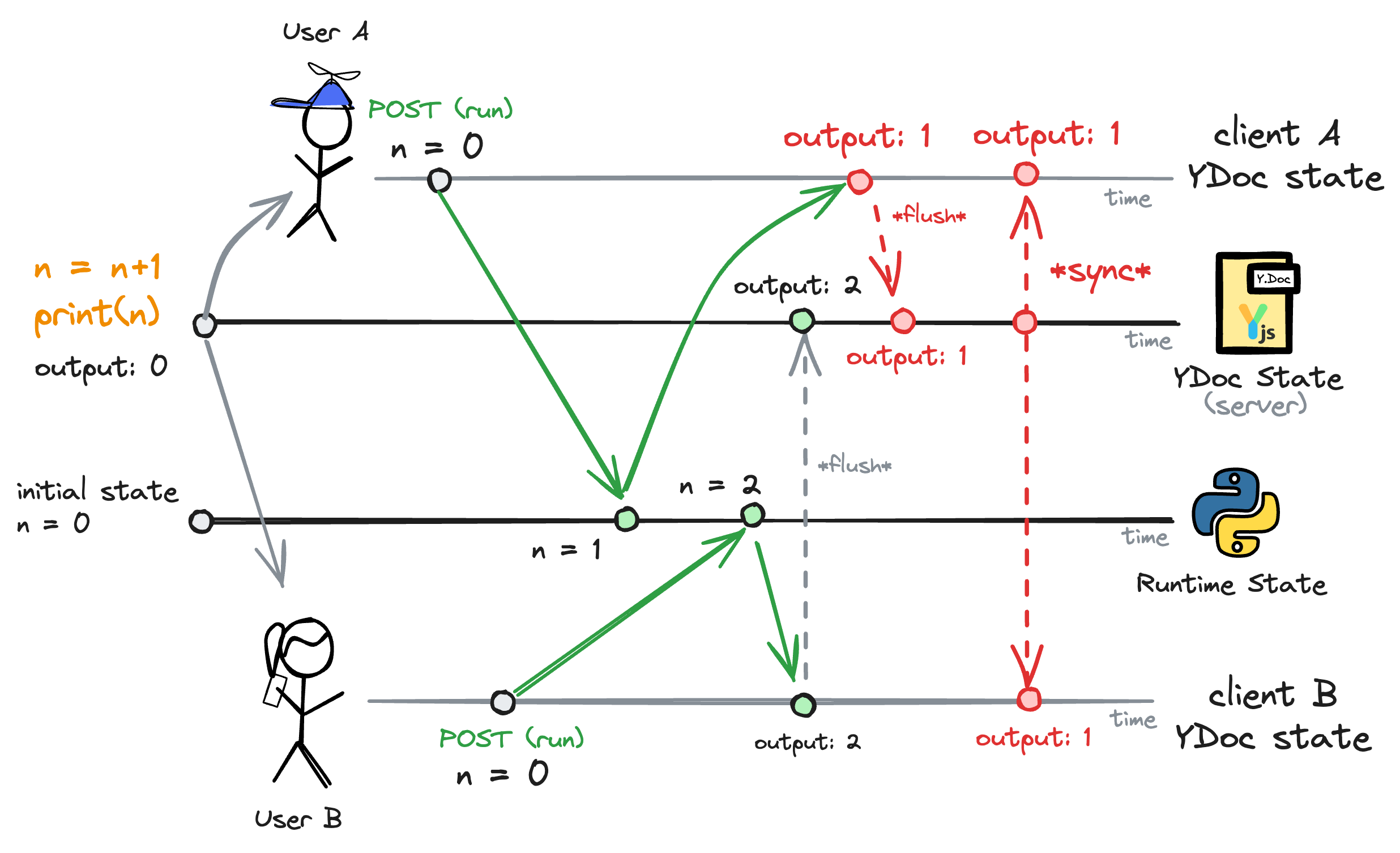
The problem with this approach is that it led to race conditions. If two people ran the same block at the same time, the last person to save their output would overwrite everyone else's output, even if they ran the block first.
Let's say user A and user B had a block that incremented a counter by 1 every time it ran. If user A ran the block and user B ran it right after, the server would run the block twice (correctly). But then if user A's response (1) arrived later than user B's (2), the server would overwrite user B's response with user A's (an incorrect 1).
This problem gets even worse when you realize that both clients will display 1 as the block's output, even though the Python runtime state is 2.
Additionally, people didn't know whether someone else was running a block because the "loading" state was only visible to the person who ran the block.
Sometimes, people would also close their browsers before the block finished executing. In that case, the code execution would alter the notebook's state, but the client wouldn't show it on the UI because it never got the response back and thus didn't update the Y.Doc object.
v2: When we finally got it right
In v2, we finally cracked multiplayer notebooks.
The way we did that was by moving all the communication between the client and the server to the Y.Doc object.
Instead of sending POST requests to the backend, the front-end would change the Y.Doc's state and the back-end would react accordingly.
Assume that you want to run a Python block, for example.
In v1, your browser would send a POST request to the backend, which would run the code and return the output. Once your browser received the output, it would write it to the Y.Doc object and flush the result back to the server.
In v2, your browser would change the block's state to run-requested. Then, the back-end would change the block's state to running and kick off the code execution. Once the code execution finished, the back-end itself would change the block's state back to idle and write the output directly to the Y.Doc object, causing all connected clients to see the output in real-time.
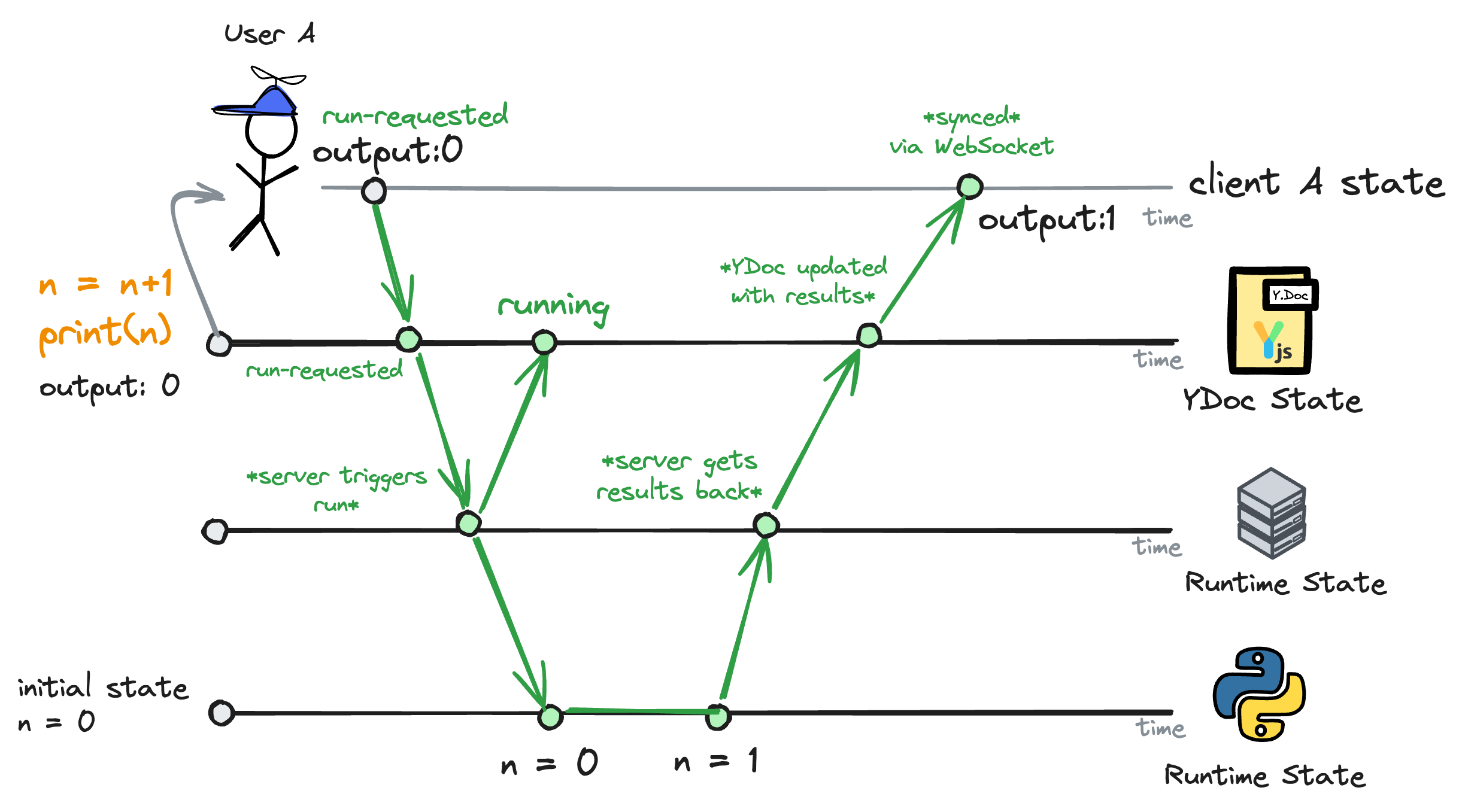
This approach eliminates race conditions because the updates to the Y.Doc are processed in order, as well as IPython executions. Here's what happens when users A and B try to run the same increment_counter block at the exact same time:
- Both clients set the block's state to
run-requested. - The server processes whichever
run-requestedevent arrives first (let's say A's) 2.1 The server tells IPython to run the code 2.2 The server changes the block's state torunning - The server processes the second
run-requestedevent (B's) 3.1 The server tells IPython to run the code 3.2 The server changes the block's state torunning4 . IPython finishes running the code for A (IPython only runs one piece of code at a time) 4.1 The server writes the output to theY.Docobject (1) - IPython finishes running the code for B
5.1 The server writes the output to the
Y.Docobject (2)
This way, the front-end would always be in sync with the back-end. If you ran a block and closed your browser before the execution finished, the back-end would still write the output to the Y.Doc object and sync it to everyone editing the notebook.
Additionally, if you and I were editing the same notebook and you ran a block, I'd see the block's state change to running because that's dictated by the Y.Doc object, not by the local browser state.
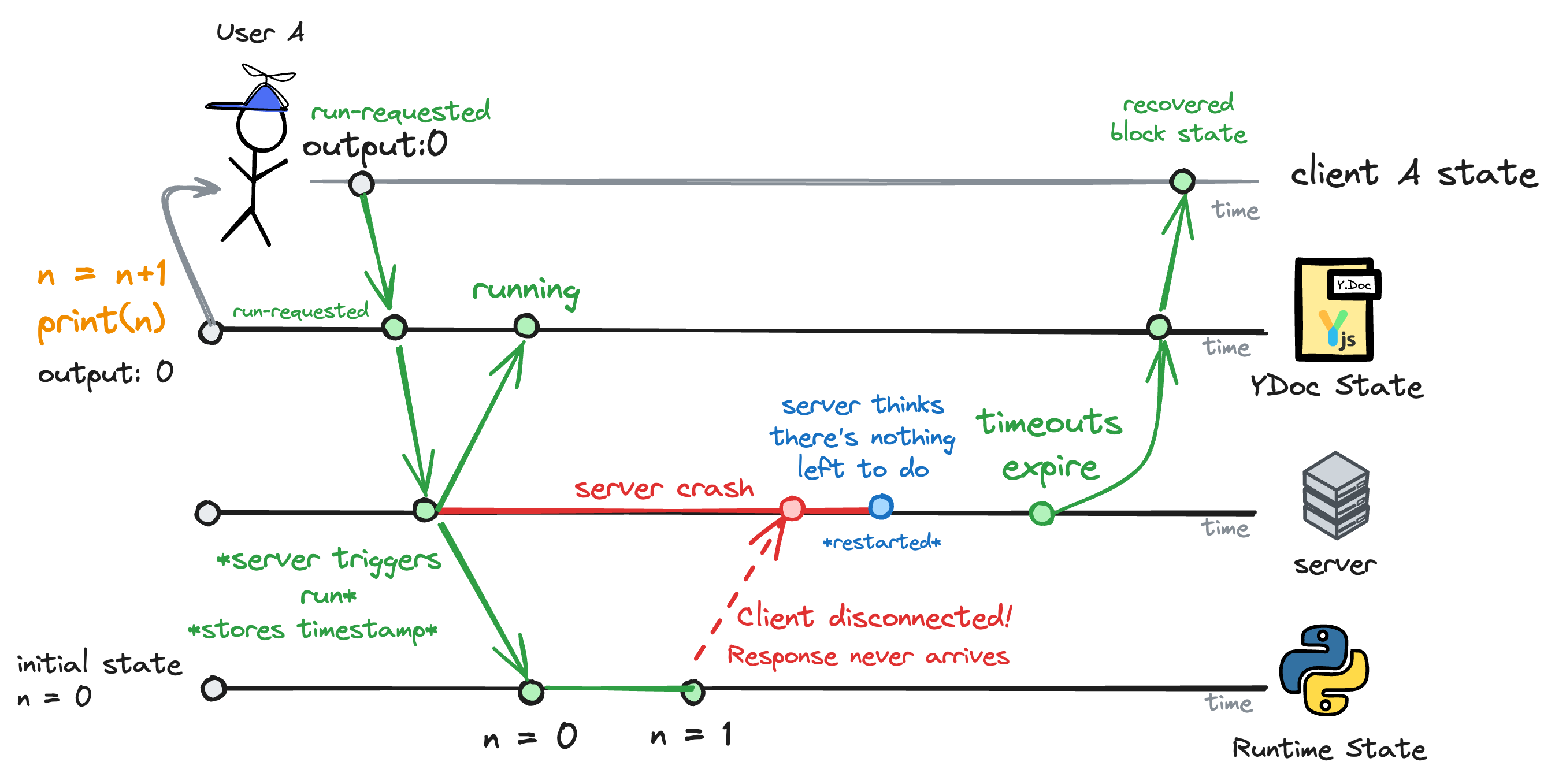
Although this approach works great in the vast majority of cases, it still has one issue: it's not resilient to back-end failures.
If you run a block and the back-end crashes during the execution, the block's state will be stuck in running forever. That's because the back-end mistakenly believes the block is still running, when it has actually completed; however, the crash prevents it from receiving confirmation from the Jupyter Server to transition the block's state back to idle.
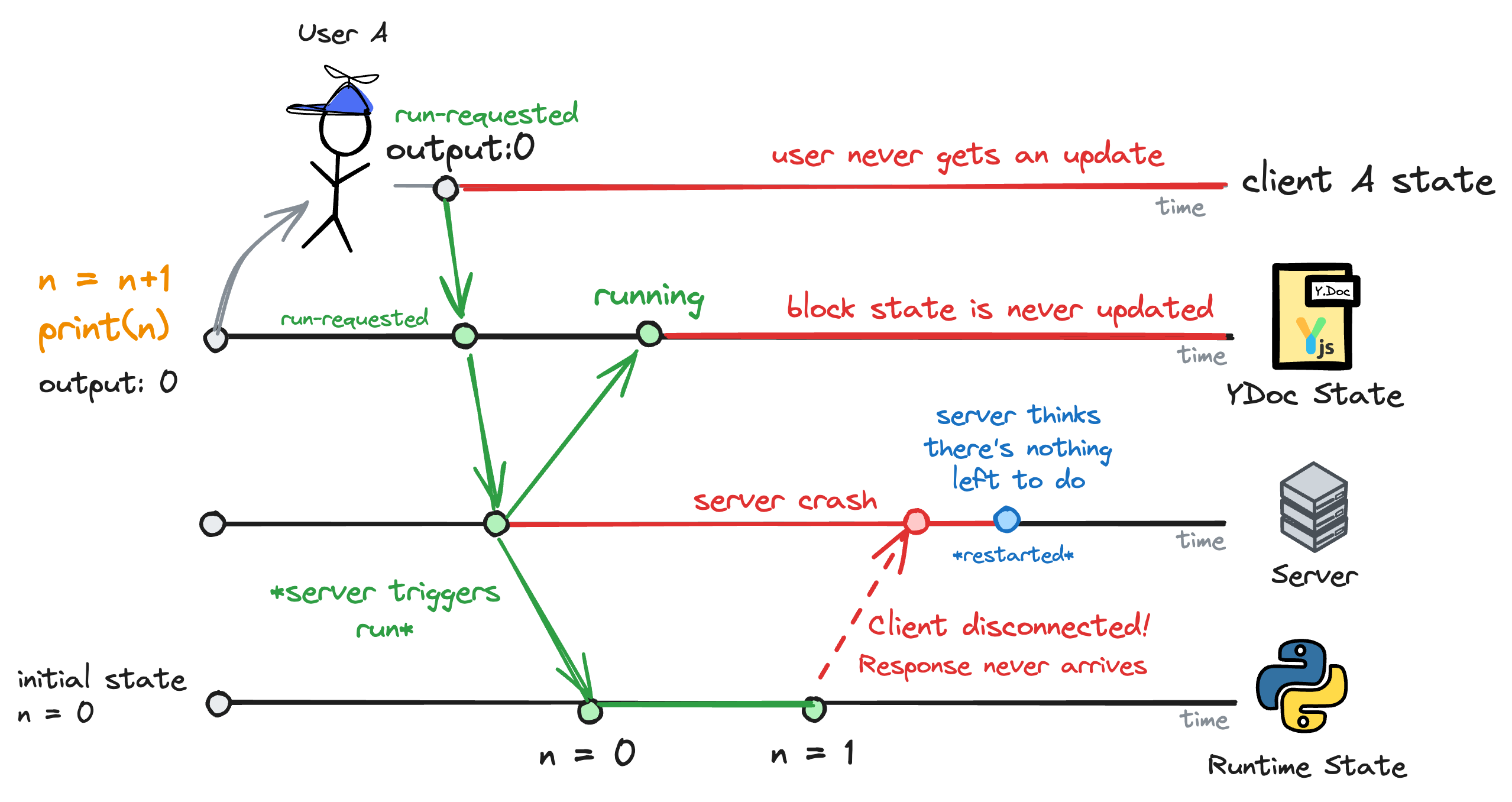
Although the back-end rarely ever crashes, it's still possible that we have to restart it when deploying new versions or even just scaling up the infrastructure.
For now, we solved this issue by timeouting the block's state and observing Jupyter Server's state, but it's a patchy solution that we're not entirely happy with.
v3: What comes next
In v3, we're planning on implementing a queue system to handle block executions.
That way, if the server crashes during the execution, the block won't get stuck in running forever. Instead, once the server comes back up, it will continue executing the block from the queue.
We don't yet know where this queue will live, but we're considering adding it to the Y.Doc object itself. That way, the queue will always be in sync with the notebook's state and any worker assigned to that document can pick up the next block to execute.
If you have ideas, suggestions, or feedback, please reach out to us at founders@briefer.cloud.
Try these multiplayer notebooks yourself
If you want to try these multiplayer notebooks yourself, you can sign up for Briefer at briefer.cloud.
Briefer is free, and we won't ask you for a credit card. We're also not going to send you spammy emails with generic PDF-ebooks, and our sales team definitely won't call you to ask if you want to upgrade to a paid plan (I am the sales team, so I can guarantee that).
Worst case scenario I'll ask you for feedback, but that's about it.
Stay hacky,
LdC