 Lucas da Costa
Lucas da CostaWhen we got into YC, we were building a product for companies to spin up development environments in the cloud. The idea was that, as software grows, it inevitably becomes too difficult to run on a single machine. At that point, people would come to us and we'd help each developer an environment in the cloud.
It didn't work.
During our batch, we amassed a thousand stars on GitHub, got to HackerNews' front page, and even had a customer pay for our product. Despite the short-term achievements, we soon realized that long-term success was probably not in the cards.
After the batch, we pivoted away from building infrastructure products.
Here's how we made that decision, the lessons we learned, and how I'd approach it differently if I had to do it again.
Too simple to be useful, or too useful to be simple
It's extremely difficult to build an infra product that's both simple and flexible enough.
When building an infrastructure product you usually have to choose whether you want to serve small or large companies first. That's because these two types of companies care about diametrically opposite things.
Large companies want flexible products that can support their peculiar infrastructure needs, even if it takes a bit longer to set up. On the other hand, small companies would rather have a simple piece of software that takes only a few minutes to set up, even if it doesn't support esoteric network settings, for example.
If you decide to build an infra product for large companies, it will almost certainly be too complex for small companies to use. Conversely, designing an infra product for small companies will make it too simple for large companies to use.

In an ideal world, you'd be able to hide complexity from small companies, while still supporting the needs of large companies. But in practice, this is nearly impossible to achieve - that's why so few infrastructure products are successful.
Small companies don't need it
We knew that selling infrastructure to large companies was going to be difficult, so we decided to focus on building a tiny product that was useful for small companies first.

Building a small product would allow us to iterate faster because we'd have customers early on, and we'd be able to get feedback from them. Then, we'd be able to raise capital to expand the product and go after larger companies.
At the time, we thought that pull-request previews were a good candidate for an MVP. We could start by deploying preview environments for pull requests, and then we would expand the product so that people could use these environments for development too.
The first version of our product was simple. It used a docker-compose.yml file to deploy pull requests and then posted a comment on the pull request with a link to the preview deployment.
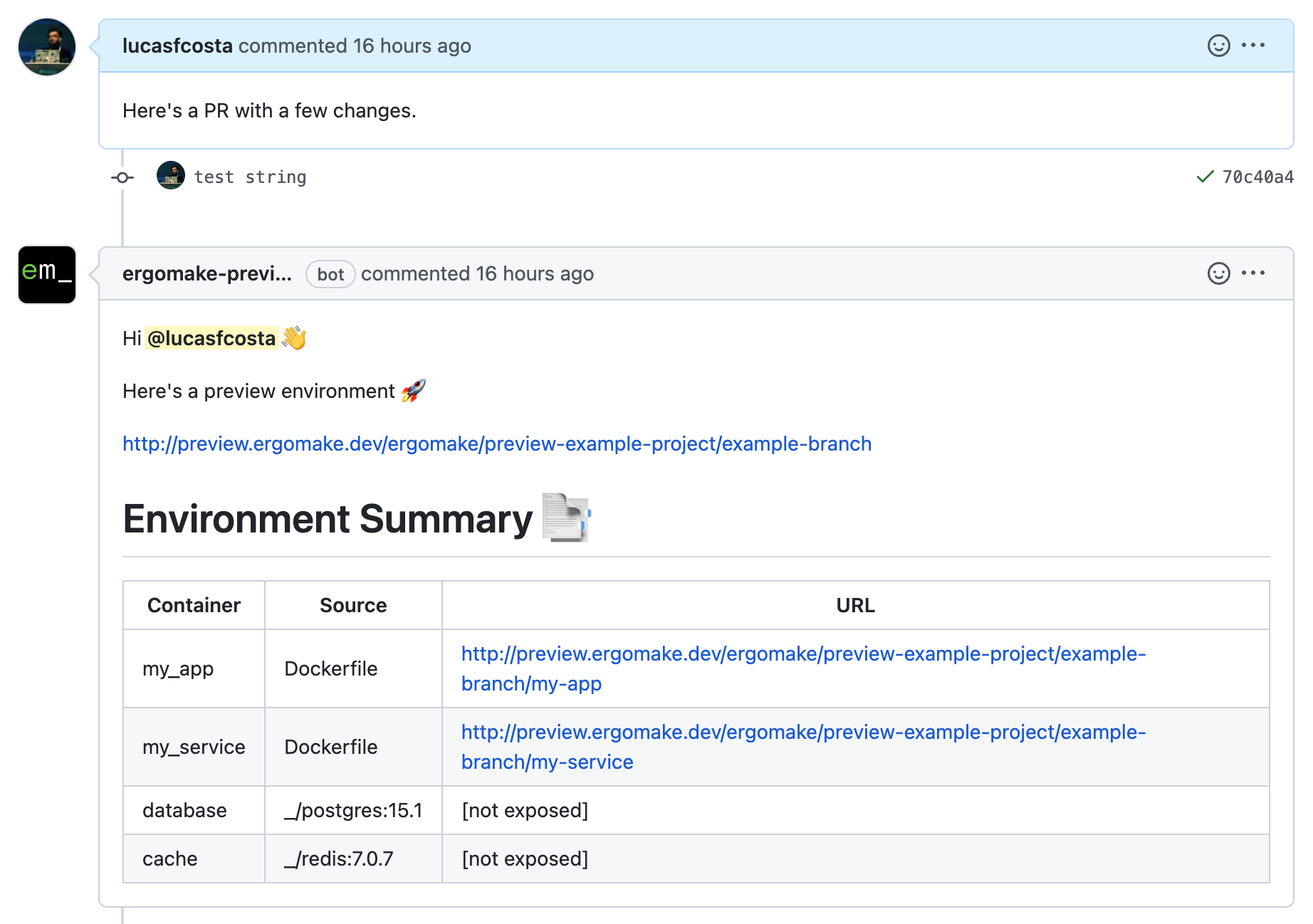
Just a few days after we put a landing page up, a small company found us and started using the product. As soon as they hit the free tier's limits, they reached out to pay.
We then tried to replicate that success with other companies, but it was extremely difficult. That's because a small company's software is usually small. Thus, they can just check out the branch and get it running in a few seconds. Having preview links was convenient, but not game-changing enough to make them pay.
The same principle applies to other infrastructure products. Even if your software is pretty simple, small companies won't care about it unless it's absolutely essential for them. And even then, they might not want to pay for it, and might just default to a free alternative.
Large companies won't trust you
After our small bet failed, we decided to rebuild our product to serve large companies, but we had a hard time getting them to trust us.
When deciding whether to purchase a product, buyers usually have the following equation in mind:

The higher the value, the more likely they are to buy.
The problem with infrastructure products is that the time-to-value and implementation effort variables are usually too high, while the perceived probability of success is too low. Consequently, no matter how amazing the dream outcome is, the final value is usually too low for buyers to move forward.
Now, let's dissect each of these variables and explain why the perceived probability of success is usually too low, and why time-to-value and implementation effort are usually too high.
Perceived probability of success

Imagine you're running a multi-billion dollar company. Would you trust a scrappy 2-person startup to handle the infrastructure that keeps your engineers productive? I wouldn't.
Sometimes, not even large providers like AWS or Google Cloud can support these companies without a lot of hand-holding. So, why would they trust a 2-person startup?
At large companies, not rocking the boat is usually more important than getting the latest and greatest technology. Consequently, they won't trust you unless you have solid proof that you're at least 10x better than the current alternative.
Effort

Creating an infrastructure product that demands little effort to implement is extremely difficult because of the very nature of the problem you're solving. You're building a product that has to be flexible enough to support all the unique needs of large companies, and that's usually complex, as we've seen earlier.
Just for engineers to understand how your product works, they'll have to spend a lot of time reading documentation, watching videos, and maybe even attending training sessions.
Furthermore, it's difficult to break down the problem into smaller pieces that can be solved independently. That's because the problems you're solving are usually interconnected, and solving one might create new problems that need to be solved.
Finally, considering all this effort, they'll probably default to having their own engineers build it, instead of buying your product. That's because they'll have more control over the final product, and they'll be able to customize it to their unique needs.
Ah, did I mention they hired tons of engineers who need to justify their next promotion?
Time-to-value

In addition to all the time engineers will have to spend learning how to use your product and set it up, it will take a while for them to see the productivity gains you promised.
That's because infrastructure products tend to deliver compounding value over time instead of delivering acute value upfront.
Take CI/CD products, for example. Testing and deploying your software for a month isn't that painful and doesn't take that much time. However, if you have to do it for a year, it becomes a huge pain point, and you'll want to automate it.
Slow feedback loops
The more feedback you have, the smaller the bets you have to make, and thus, the less risk you have to take.
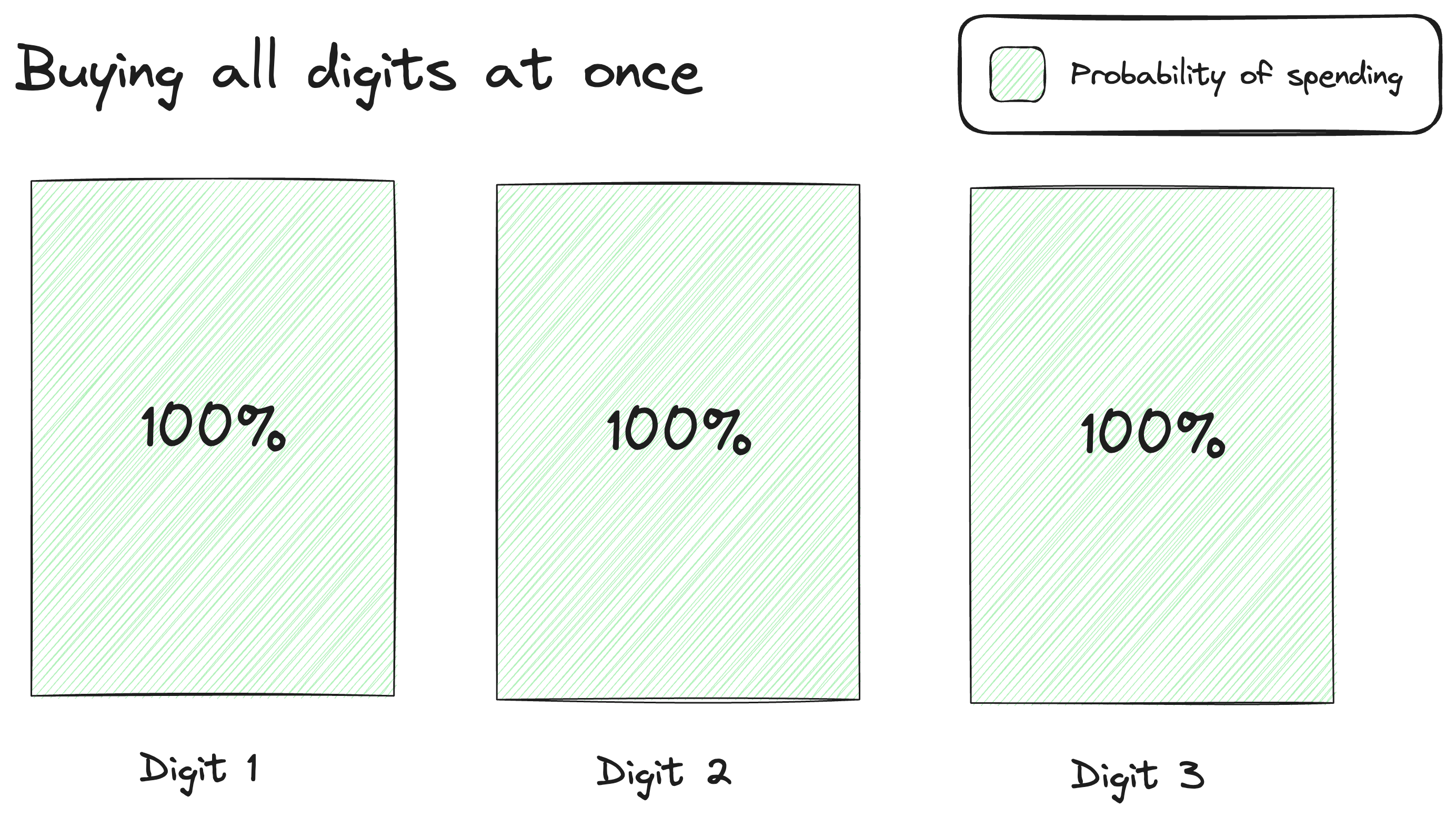
Think about buying 3-digit lottery tickets, for example. Paying $1 for each digit as numbers are drawn is better than paying $3 for all three digits at once.
If you have to buy all three digits at once, the likelihood of guessing all three is only 1%, and each attempt costs you $3.
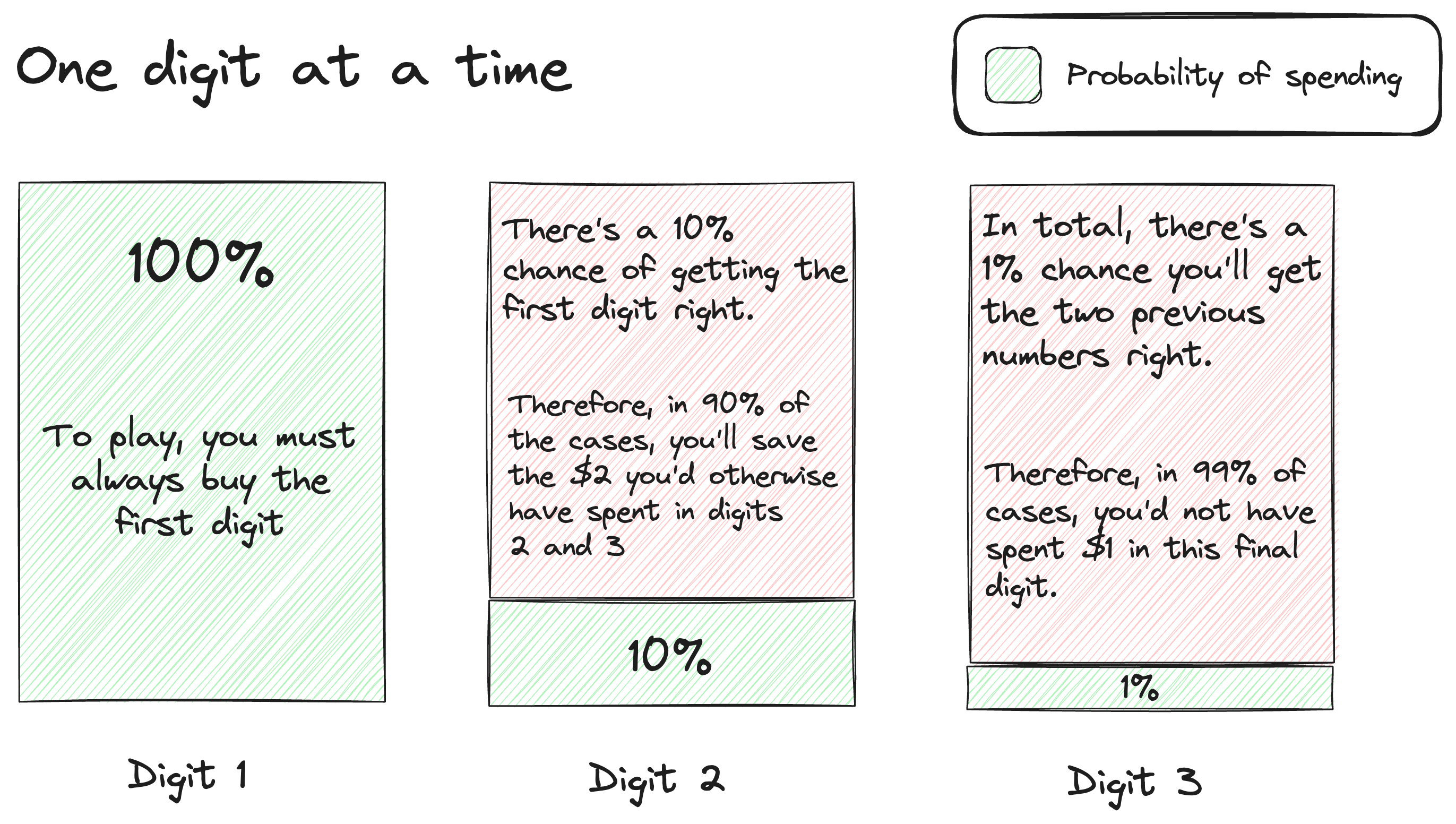
On the other hand, if you pay $1 per digit, you can decide whether to continue as soon as the first number is drawn. If you get it right, you can pay for the next; if not, you can give up sooner and lose less money.
In this case, there’s only a 10% chance you’ll buy the second number and a 1% chance you’ll buy the third. Therefore, each failed attempt will cost you less, but the overall likelihood of winning is still the same.
Building an infra product is like buying all three digits at once. You have to make a large bet upfront, and you won't know if you're building the right thing until you get your first customer. That's because it's difficult for large companies to trust you, and, even when they do, slow sales cycles and long implementation times will elongate the feedback loop.
Additionally, it will take longer to have a large enough sample size to know if your product is any good, and to understand whether a request is a one-off or a recurring need for most customers.
How I would approach it differently if I had to do it again
When picking a startup idea, you're also picking a set of problems that come with it. Ultimately, all problems are solvable, but some are more difficult than others for a given team.
Even though I'm glad we pivoted away from infrastructure products, I still believe they're a great opportunity for the right team, so here's how I'd approach it differently if I had to do it again:
- I'd insist on selling to small companies first. Instead of investing time trying to sell to large companies, I'd invest time in rethinking the product so that it's useful for small companies. That's a piece of advice we got from PG himself, and it was spot on.
- I'd accept having to make larger bets and act accordingly. Given the slow feedback loop, I'd be more inclined to think long-term and make larger bets, like building more features upfront and building a community around the product, even if they're not paying customers, and probably won't be for a while (or ever).
- I'd cut scope as much as possible and avoid being seen as a replacement for existing solutions. I think this point is valid for all startups, but it's especially true for infrastructure products because switching infrastructure usually takes longer than anything else. Therefore, I'd think harder about whether I can build something small and less critical to go alongside existing solutions.
How these learnings helped us pick our next idea
The worst part of building an infrastructure product was the slow feedback loop, so our first criteria for picking our next idea was to find a problem that we could offer a packaged solution for, and that we could sell to small and medium companies first. That solution also had to be easy to use, and the time to value had to be as short as possible.
Considering these criteria, we then brainstormed a few hypotheses and ran approximately fifty customer interviews to validate them.
We then landed on what we're doing today: a product that helps companies generate unique insights by using code.
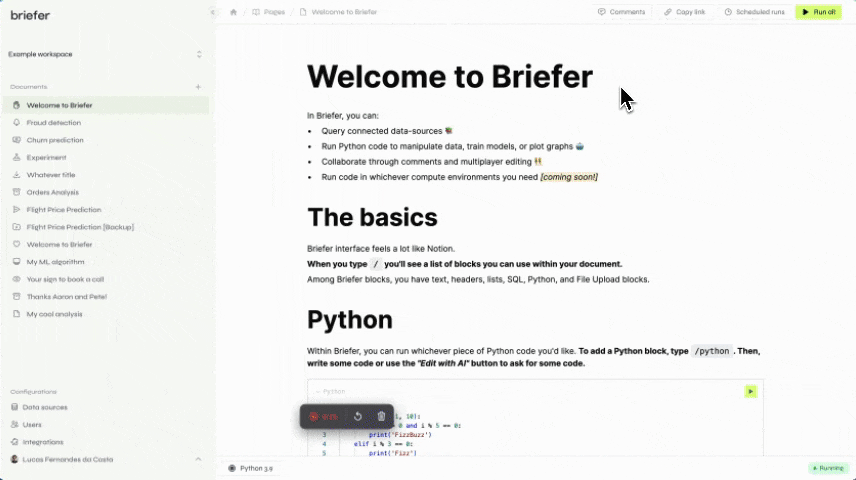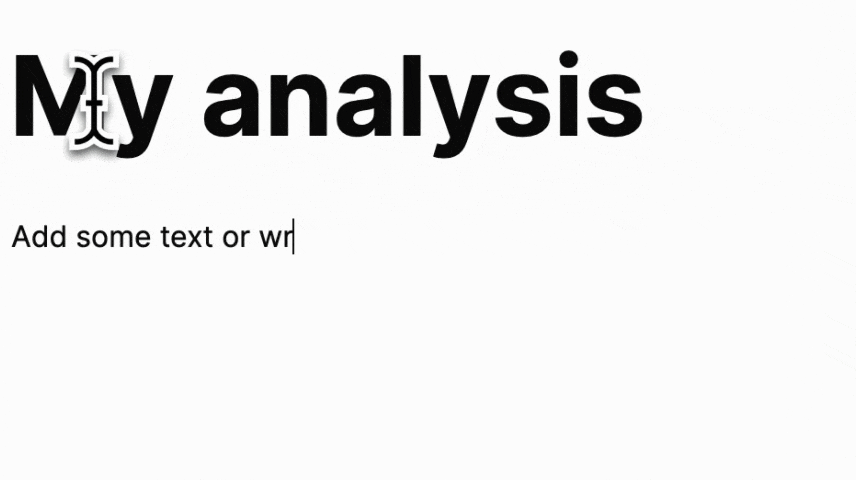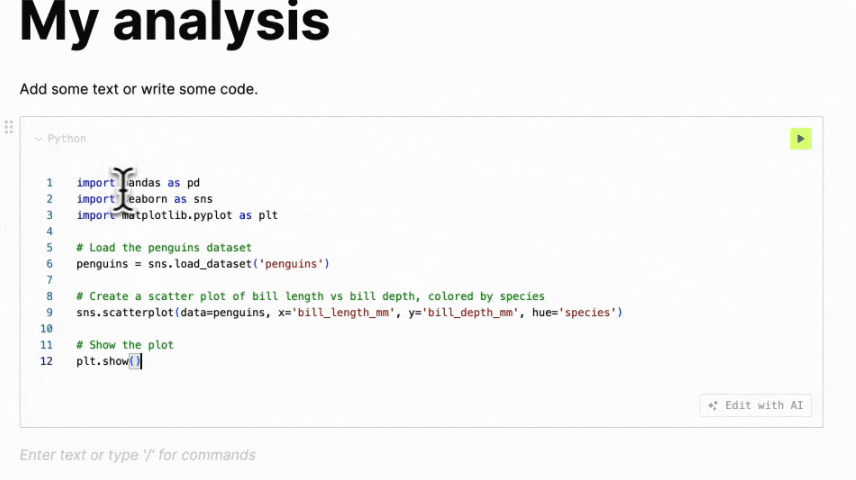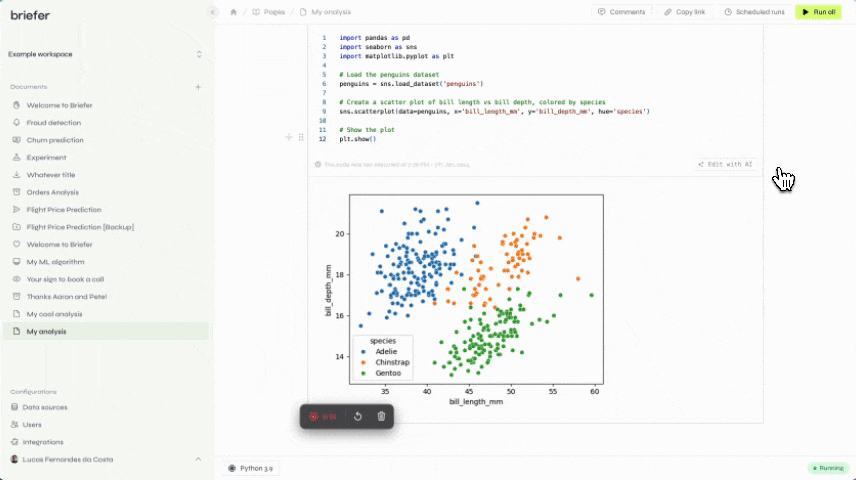
The reason Briefer turned out to be a great fit for us is that:
- Time-to-value is extremely short. Instead of spending days reading documentation and setting up the product, customers can just log in and start generating insights.
- It appeals to both small and large companies. Small companies usually love Briefer because their engineers can write code to generate insights, and they don't have to wait for a data team to do it for them. Large companies love it because they can use it to build more advanced analyses, data apps, and predictive models.
- We don't have to replace existing solutions. While some companies replace their BI tools with Briefer, most use it alongside them because traditional BI tools can't generate the insights Briefer can, nor can they be used to build data apps or predictive models.
In the end, we're glad we went through the infrastructure journey, even though it was tough. It taught us a lot about building products, and it helped us land on a better idea.
I'm extremely thankful for the YC partners, our batchmates, and the YC alumni who helped us along the way. Many of these learnings wouldn't have been possible without their help.
Finally, if you want to try Briefer, or even if you're not sure it's the right choice, please feel free to visit our website and book an intro call with us. We'd love to hear from you.