
The digital economy depends on decisions made in real time. A millisecond delay in processing a payment can cost revenue. A one-second lag in spotting a cyberattack creates risk. Every moment without insight from live sensor data is a missed opportunity or a failure waiting to happen.
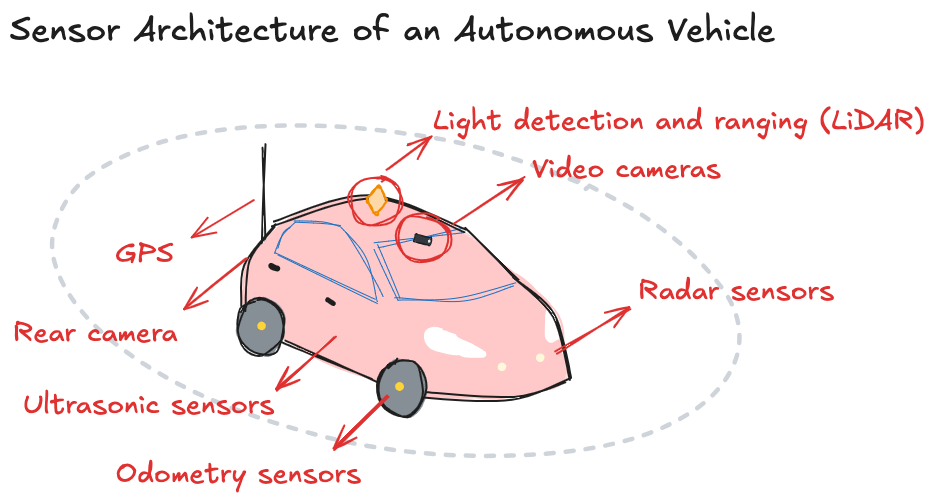
Take autonomous vehicles: they rely on continuous input from cameras and sensors. If the AI reacts to data that’s even seconds old, it can miss a pedestrian, a traffic light change, or a sudden obstacle. Delayed decisions can have serious consequences.
Real-time AI agents can help close that gap. While traditional analytics asked, "What happened?", real-time AI asks, "What’s happening now? What should we do next?" In a world where data loses value with every passing second, speed isn’t just an advantage; it’s a requirement. You can learn more about AI for data analysis in our guide.
Why Real-Time Matters
Real-time data is information that’s processed as it's generated, not minutes or hours later, but in milliseconds. Unlike batch processing, which waits to collect data before analyzing it, real-time systems enable immediate insight and action.
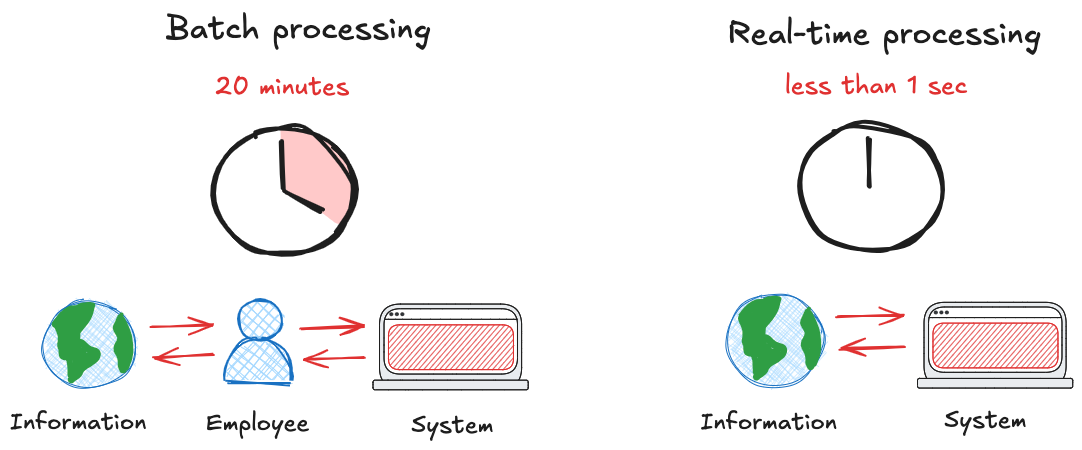
Traditional batch processing introduced delays by design. Insights arrived late, decisions lagged, and systems couldn't adapt fast enough. In high-stakes environments like finance, logistics, healthcare and cybersecurity, waiting even a few seconds can mean missed opportunities or serious failures.
Batch systems were also brittle. Scaling to larger data volumes or integrating new sources often meant reengineering entire pipelines. Real-time processing flipped the script: it handles streaming data as it arrives, reduces latency to near-zero, and scales horizontally across dynamic workloads.
The shift to real-time analysis redefined what's possible. Real-time pipelines are now the backbone of modern AI systems, powering everything from fraud detection to personalized recommendations. In short: if your data isn’t live, your decisions aren’t either.
Architectural Patterns
Real-time AI pipelines must balance two forces: speed and intelligence. The faster the system, the harder it is to run complex models. Two core patterns have emerged to manage this trade-off—each optimized for different performance and learning needs.
Event-Driven vs Micro-Batch
Event-driven architectures treat each data point as a discrete event that triggers immediate processing. When a user clicks a link, uploads a file, or makes a purchase, the system responds within milliseconds. This approach excels in scenarios where individual events carry high value or where delayed responses create negative user experiences. AI for Kafka streams exemplifies this pattern, where machine learning models process each message as it arrives, enabling real-time personalization, fraud detection, and anomaly identification.
The elegance of event-driven systems lies in their simplicity: data flows through a pipeline of processing stages, with AI models acting as intelligent filters and transformers at each step. For example, marketing teams can Identify Website Visitors in real-time and trigger personalized campaigns. A streaming recommendation engine might process a user's click event, update their preference profile, regenerate recommendations, and push updates to their interface: all within the time it takes to load a web page.
Micro-batch processing, by contrast, accumulates small groups of events over brief time windows (typically seconds or minutes) before processing them together. This approach sacrifices some latency for computational efficiency, leveraging the parallel processing capabilities of modern hardware. Spark Streaming and similar frameworks excel at this pattern, processing thousands of events simultaneously through vectorized operations and GPU acceleration.
The choice between these patterns depends on the specific requirements of your AI workload. High-frequency trading systems demand event-driven architectures where microseconds matter. Business intelligence dashboards can often tolerate micro-batch processing, gaining efficiency without sacrificing user experience.
Agentic AI for Continuous Learning
Agentic AI shifts the role of AI systems from passive responders to active participants in the data stream. Instead of just reacting to events, these systems learn continuously, adapt in real time, and make decisions about how to handle future data without waiting for retraining cycles or human input.
Think of it as moving from automation to autonomy. Inspired by the concept of active inference in cognitive science, agentic AI doesn't just wait for signals, instead it looks for them. It forms hypotheses, tracks evolving patterns, and updates its internal models as new data arrives. For example, an agentic AI monitoring network traffic won’t just flag known threats; it learns what "normal" looks like and evolves to detect emerging attacks on its own.
Continuous learning in streaming environments isn’t simple since real-time data changes continuously. Agentic systems tackle this using:
-
Online learning, where models update with every new data point
-
Dynamic ensembles, which combine multiple models and reweight them based on live performance
-
Context-aware logic, where AI agents adjust their strategies based on the behavior of the environment
The result: systems that don’t just keep up with the data, but grow with it.
Tech Stack Comparison
A real-time AI pipeline has five essential components: ingestion, processing, modeling, storage, and visualization. Each must operate with low latency, scale efficiently, and adapt to changing data.
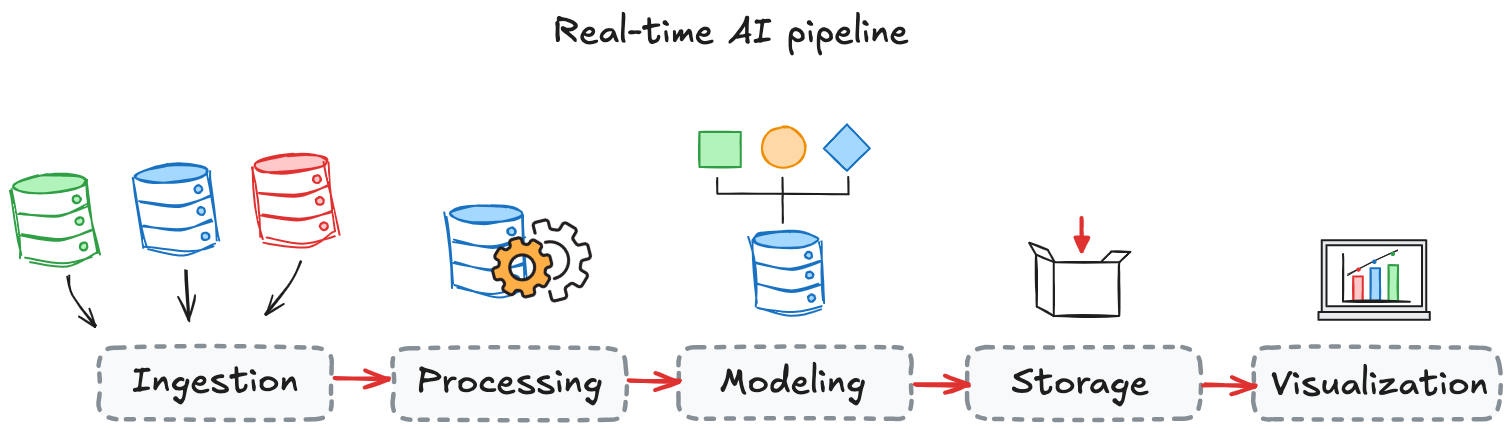
Kafka is the core of most streaming systems, offering reliable, high-throughput ingestion. Kafka Streams supports inline processing, while Kafka Connect handles system integration. For more advanced workloads, Apache Flink adds event-time support and stateful operations. Pulsar extends this with multi-tenancy and built-in geo-replication.
For AI workloads, MLflow supports live model serving and tracking. Kubeflow runs scalable ML pipelines on Kubernetes. Cloud-native options like AWS Kinesis with SageMaker or Google Dataflow with Vertex AI simplify deployment and scaling.
Storage needs to support fast writes and queries. InfluxDB and TimescaleDB work well for time-series data. Apache Druid handles fast analytics on streaming input. For large-scale durability and global access, Cassandra and DynamoDB are standard.
Visualization is where decisions happen. Most tools lag behind the stream. Briefer doesn’t. It connects directly to Kafka, Redis, and time-series stores, and updates dashboards in real time. Fraud scores, predictions, anomaly alerts—delivered instantly, without polling or refresh delays. It’s built for real-time AI, not static reporting.
Emerging tools like Apache Beam, Apache Arrow, and edge runtimes like Jetson and OpenVINO extend what’s possible, but the core remains: stream fast, score fast, and see results without delay. Briefer makes that last part work.
To dive deeper into AI tools for data analysis, see the Best AI Tools for Data Analysis guide.
Governance & Observability
Real-time AI systems can break fast and silently. Bad data, delayed labels, or slow consumers can cascade into faulty decisions. You need monitoring that catches issues as they happen; not after.
Data Quality: Validate at Ingest
Streaming pipelines can’t afford to process broken data. Format changes (schema drift), missing fields, and unexpected values will crash your downstream logic or silently corrupt your model inputs. A thorough exploratory data analysis is crucial to understand potential issues before they enter the pipeline.
Use a schema registry (like Confluent) to enforce data structure and version control. Run real-time validation on incoming data: check for nulls, unexpected types, and outliers before inference happens.
This is prevention, not recovery. If you’re validating after inference, it’s already too late.
Model Monitoring Without Labels
Real-time systems often operate without immediate ground truth. You make a prediction now, but don’t find out if it was right until hours or days—later.
To fill the gap, monitor proxy metrics that correlate with model performance:
- In fraud detection: average risk scores, decision distribution, chargeback rate over time.
- In recommendations: click-through rate, engagement rate, time-to-interaction.
Track these continuously. Sudden changes usually signal drift, upstream bugs, or degraded model behavior. You don’t need labels to know when something’s wrong.
System Metrics That Matter
Most infrastructure metrics like CPU, memory, disk don’t tell you if your pipeline is healthy. These do:
-
Consumer lag: Shows how far behind your processors are. If it grows, your model is working with stale data.
-
Throughput: How much data you're processing per second. Drops signal slowdowns or bottlenecks.
-
End-to-end latency: Time from ingestion to output. If this spikes, your “real-time” system isn’t.
-
Queue depth: Unprocessed data piling up means you're not keeping up—and failure is coming.
Track these across the full pipeline using tools like Prometheus, Grafana, or Datadog. They tell you if your system is falling behind before users notice.
Alerting: Reduce Noise, Increase Signal
Static thresholds fail in streaming systems. Data is volatile, and normal variation triggers constant false alarms. The result? Teams ignore alerts.
Instead, use dynamic alerting. Set baselines from recent behavior and alert on significant deviations—like a 50% drop in throughput or a sudden spike in consumer lag. This catches real issues without flooding you with noise. If your alerts aren’t trusted, they’re useless.
Cost Optimization Tips (Serverless, Spot Instances)
The economic efficiency of real-time AI systems depends heavily on infrastructure choices and optimization strategies. Cloud computing has transformed the cost structure of data processing, enabling pay-per-use models that align costs with actual usage rather than peak capacity.
Serverless computing platforms like AWS Lambda, Google Cloud Functions, and Azure Functions excel at handling variable workloads where processing demands fluctuate dramatically. For AI workloads, serverless functions can process individual events or small batches of events without maintaining idle resources. The key limitation is execution time—most serverless platforms limit functions to 15 minutes or less, making them suitable for lightweight AI models but not for training large neural networks.
Spot instances provide significant cost savings for fault-tolerant workloads. These instances use excess cloud capacity at reduced prices, but can be terminated with short notice when capacity is needed elsewhere. Stream processing systems can leverage spot instances by designing for node failures—maintaining replicas across multiple instances and using checkpointing to enable rapid recovery.
Container orchestration platforms like Kubernetes enable sophisticated resource management strategies. Horizontal Pod Autoscaling automatically adjusts the number of processing nodes based on CPU utilization, memory usage, or custom metrics like message queue depth. Vertical Pod Autoscaling adjusts resource allocations for individual containers, optimizing efficiency without manual intervention.
Storage costs often dominate the economics of big data systems. Implementing data lifecycle policies that automatically move older data to cheaper storage tiers—like AWS S3 Glacier or Google Cloud Archive—can reduce costs by 90% or more. For streaming systems, this means designing retention policies that balance data availability with storage costs.
Edge computing offers another cost optimization opportunity by processing data closer to its source. Rather than streaming all sensor data to centralized cloud infrastructure, edge devices can run lightweight AI models locally, transmitting only summary statistics or anomaly alerts. This approach reduces bandwidth costs and improves response times while maintaining system functionality.
Case Study Clips (E-Commerce, IoT)
Real-world implementations of real-time AI systems demonstrate both the potential and the practical challenges of these architectures. Two domains—e-commerce and IoT—illustrate different aspects of streaming AI systems.
E-commerce platforms process millions of user interactions daily, each representing an opportunity for personalization and optimization. A major online retailer implemented a real-time recommendation engine that processes user clicks, views, and purchases to update product recommendations within milliseconds. The system uses collaborative filtering algorithms running on Apache Flink, processing events from web applications, mobile apps, and email interactions.
The technical architecture centers on event streaming through Kafka, with separate topics for different event types: page views, add-to-cart events, purchases, and search queries. Machine learning models consume these streams, updating user profiles and product affinity matrices in real-time. The recommendation engine uses these updated profiles to generate personalized product rankings, which are cached in Redis for sub-millisecond retrieval.
The business results proved compelling: real-time personalization increased conversion rates by 15% and average order value by 8%. More importantly, the system enabled entirely new features like abandoned cart recovery, where users receive personalized offers within minutes of leaving items in their shopping cart.
IoT deployments present different challenges, emphasizing edge processing and bandwidth optimization. A manufacturing company deployed AI-powered predictive maintenance across hundreds of production machines, each equipped with vibration sensors, temperature monitors, and acoustic sensors generating thousands of data points per second.
The solution combines edge and cloud processing: lightweight anomaly detection models run on edge devices, identifying potential issues and transmitting alerts to centralized systems. Normal operational data is summarized and transmitted in batches, while anomalous patterns trigger immediate alerts with full sensor data.
Machine learning models use autoencoder neural networks to learn normal operational patterns for each machine type. When sensor readings deviate significantly from learned patterns, the system generates maintenance alerts and automatically schedules inspections. The approach reduced unplanned downtime by 40% while decreasing maintenance costs through more targeted interventions.
Further Reading & Courses
To go deeper into building real-time AI systems, here are research-backed, applied resources that focus on streaming data, scalable ML, and system design.
Courses
-
Real-Time Data Processing with Apache Kafka – Coursera (Confluent): Hands-on with Kafka, producers/consumers, and stream processing.
-
Scalable Machine Learning on Big Data – edX (BerkeleyX): Covers distributed ML, Spark Streaming, and pipeline design.
-
MLOps Specialization – Coursera (DeepLearning.AI): Includes model serving, monitoring, and CI/CD—relevant for real-time deployment.
Reading
-
Designing Data-Intensive Applications by Martin Kleppmann – The go-to book on building reliable, scalable systems. Strong emphasis on stream processing and stateful architectures.
-
Streaming Systems by Tyler Akidau (Google) – Core text on event time, windowing, and the challenges of stream-first thinking.
-
"The Evolution of Real-Time Machine Learning" (Arxiv, 2022) – A concise overview of architectures for online inference, feedback loops, and latency trade-offs.
Papers and Industry Case Studies
-
Uber’s Michelangelo and ByteDance’s Fuxi (both open-sourced summaries) explain production-scale real-time ML stacks.
-
Google’s TFX + TensorFlow Serving pipelines show how to integrate streaming with trained models.
-
"Drift Detection in Streaming ML Systems" – SIGMOD 2021. Real-world techniques for monitoring concept drift in live pipelines.